Bitcoin中Base58Check編碼
[原文]Base58二進位制到文字編碼被稱為 Base58Check,用於編碼比特幣地址。
更一般地說,Base58Check 編碼用於將比特幣中的位元組陣列編碼為人類可分類的字元串。
背景
最初的比特幣客戶端原始碼解釋了 base58 編碼背後的原因:
base58.h:
1
2
3
4
5
6
// 為什麼 base-58 而不是標準的 base-64 編碼?
// - 不希望 0OIl 字元在某些字型和字型中看起來相同
//可以用來建立視覺上相同的賬號。
// - 具有非字母數字字元的字元串並不像帳號那麼容易被接受。
// - 如果沒有標點符號,電子郵件通常不會換行。
// - 如果全部是字母數字,Doubleclicking 會將整個數字選為一個單詞。
Base58Check的功能
Base58Check 具有以下功能:
- 一個任意大小的 payload( 這個 payload 其實就是公鑰的 HASH160 的雙次 hash 值 )。
- 由容易區分的大寫和小寫字母組成的一組 58 個字母數字符號(
0OIl不使用)( 主要的原因還是因為可能會產生歧義 ) - 一個位元組的 version/application 資訊。對於這個位元組比特幣地址使用 0x00(未來的可能使用 0x05 )。
- 四個位元組(32 位)基於 SHA256 的錯誤校驗碼。此校驗碼可用於自動檢測並可能更正印刷錯誤。
- 保留資料中前導零的額外步驟。(這裡應該更深入地進行分析才是,但是現在真不太明白這裡面的意思。)
建立一個 Base58Check 字元串
Base58Check 字元串是從 version/application 位元組和 payload 建立的,如下所示。
- 獲取 version 位元組和 payload 位元組,並將它們連線在一起(按位元組)。
- 取 SHA256 的前四個位元組( SHA256 (步驟 1 的結果))( 也應該是前面提到的那四個位元組的事情 )
- 將步驟 1 的結果和步驟 2 的結果連在一起(按位元組順序)。
- 處理步驟3的結果 - 一系列位元組 - 作為單個大端序號 ,使用正常的數學步驟( bignumber division )和下面描述的 base-58 字母表轉換為 base-58 。結果應該被標準化為沒有任何前導的 base-58 零(字元
1)。( 這裡注意前導 0 對應的 Base58Check 是1 ) - 在 base58 中值為零的前導字元
1被保留用於表示整個前導零位元組,就像它處於前導位置時一樣,沒有值作為 base-58 符號。必要時可以有一個或多個前導1來表示一個或多個前導零位元組。計算第3步結果的前導零位元組數(對於舊的比特幣地址,至少有一個用於版本/應用程式位元組;對於新地址,將永遠不會有)。每個前導零位元組在最終結果中應由其自己的字元1表示。 - 將步驟5中的1與步驟4 的結果連線起來。這是 Base58Check 的結果。
在描述比特幣地址技術背景的頁面上提供了一個更詳細的例子。
編碼比特幣地址
比特幣地址是使用以下任一項的雜湊的 Base58Check 編碼實現的:
- Pay-to-script-hash(p2sh):有效載荷是:其中 redeemScript 是錢包知道如何消費的指令碼; 版本(這些地址以數字
3開頭) RIPEMD160(SHA256(redeemScript))0x05 - 支付到PUBKEY雜湊( p2pkh ):有效載荷是其中 ECDSA_publicKey 是錢包知道的私有金鑰的公共金鑰; 版本(這些地址以數字
1開頭)RIPEMD160(SHA256(ECDSA_publicKey))0x00
在這兩種情況下得到的雜湊總是恰好為 20 個位元組。這些是大端(最重要的位元組在前)。(注意那些限制前導 0x00 位元組的數字編碼實現,或者預先增加額外的 0x00 位元組來表示符號 - 你的程式碼必須正確處理這些情況,否則你可能會生成可以傳送到但看不到的有效地址 -導致硬幣的永久損失。)
編碼一個私鑰
- *Base58Check 編碼也用於編碼錢包匯入格式中的ECDSA 私鑰** 。除了 0x80 用於 version/application 位元組,並且有效載荷是 32 位元組而不是 20 (比特幣中的私鑰是單個 32 位元組無符號的大端整數)之外,它與比特幣地址完全相同。對於與未壓縮的公鑰相關的私鑰,這種編碼總是會產生一個以
5開頭的 51 個字元的字元串,或者更具體地說5H,5J或5K。
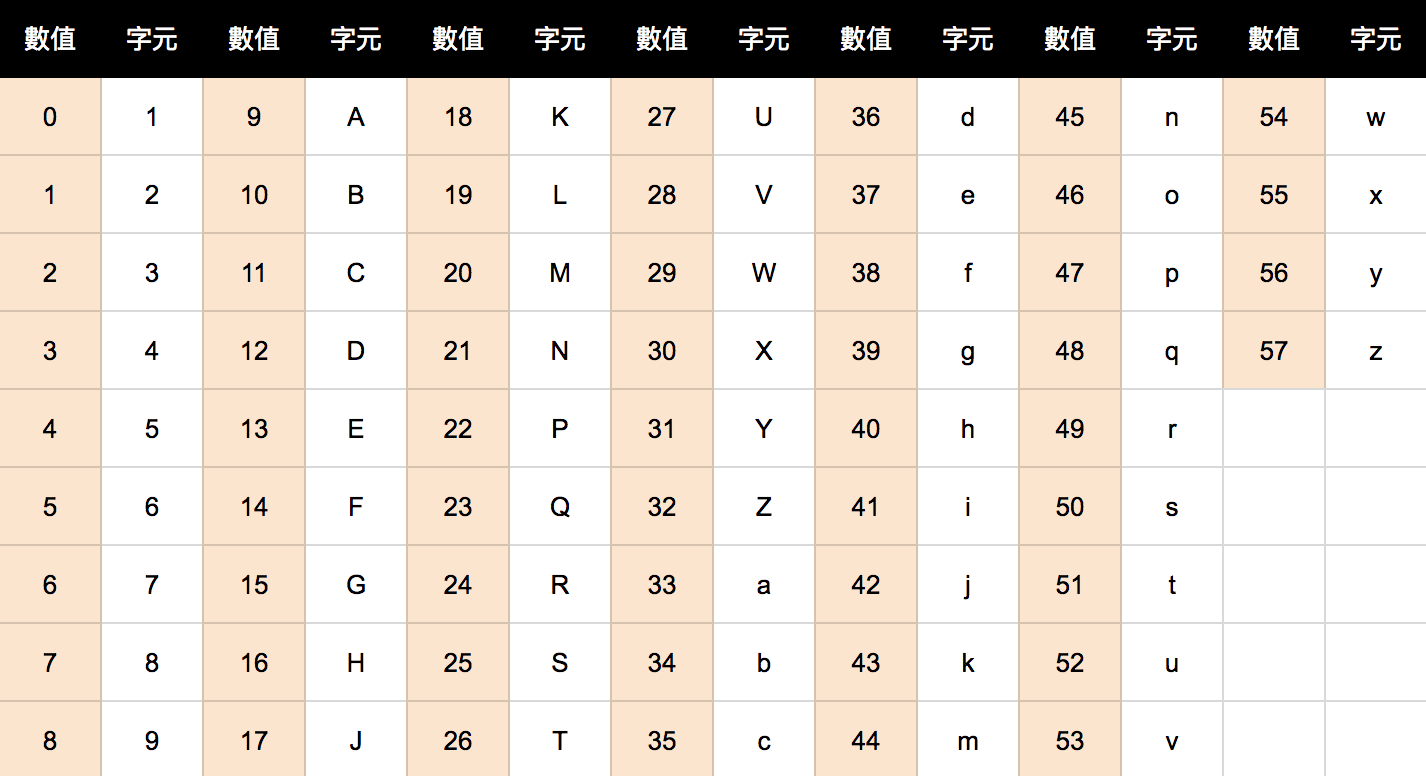
Base58 符號圖表
比特幣中使用的 Base58 符號圖特定於比特幣項目,並不打算與比特幣之外使用的任何其他 Base58 實現(排除的字元為:0, O, I和l)相同。
| 值 | 字元 | 值 | 字元 | 值 | 字元 | 值 | 字元 |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 2 | 2 | 3 | 3 | 4 |
| 4 | 5 | 5 | 6 | 6 | 7 | 7 | 8 |
| 8 | 9 | 9 | A | 10 | B | 11 | C |
| 12 | D | 13 | E | 14 | F | 15 | G |
| 16 | H | 17 | J | 18 | K | 19 | L |
| 20 | M | 21 | N | 22 | P | 23 | Q |
| 24 | R | 25 | S | 26 | T | 27 | U |
| 28 | V | 29 | W | 30 | X | 31 | Y |
| 32 | Z | 33 | a | 34 | b | 35 | c |
| 36 | d | 37 | e | 38 | f | 39 | g |
| 40 | h | 41 | i | 42 | j | 43 | k |
| 44 | m | 45 | n | 46 | o | 47 | p |
| 48 | q | 49 | r | 50 | s | 51 | t |
| 52 | u | 53 | v | 54 | w | 55 | x |
| 56 | y | 57 | z |
編碼 address_byte_string 的演算法(由1-byte_version + hash_or_other_data + 4-byte_check_code組成)是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
code_string = "123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz"
x = convert_bytes_to_big_integer(hash_result)
output_string = ""
while(x > 0)
{
(x, remainder) = divide(x, 58)
output_string.append(code_string[remainder])
}
repeat(number_of_leading_zero_bytes_in_hash)
{
output_string.append(code_string[0]);
}
output_string.reverse();
版本位元組
以下是一些常見的版本位元組:
| 小數版本 | 領導的象徵 | 使用 |
|---|---|---|
| 0 | 1 | Bitcoin pubkey hash |
| 5 | 3 | Bitcoin script hash |
| 21 | 4 | Bitcoin (compact) public key (proposed) |
| 52 | M or N | Namecoin pubkey hash |
| 128 | 5 | Private key |
| 111 | m or n | Bitcoin testnet pubkey hash |
| 196 | 2 | Bitcoin testnet script hash |
地址字首列表是一個完整的列表。
也可以看看
原始碼
- “Satoshi”C ++ codebase(解碼和編碼,不需要外部庫)
- libbase58 C 程式碼(解碼和編碼,不需要外部庫)
- Base58 在 Perl 中解碼,編碼和驗證
參考和引用
總結
關於比特幣地址知識,在精通比特幣中有詳細地介紹,這裡我們不做更多的介紹,這篇文章是我翻譯的結果。
在之前我們分析過橢圓曲線的知識,對於確定性錢包的知識我們也做了相關地介紹,還有就是分層確定性錢包的知識。
-
*另外 Base58Check 還有一個極大的好處就是可以校驗地址是不是正確的,因為 Base58 生成的時候是加入了校驗碼** 。我覺得比特幣團隊做的真的是很棒不是嗎?詳情可以參考:為什麼以太坊地址中沒有校驗值?
-
*對於比特幣地址也要特別注意一下,地址類型也就是 version/appication 欄位其實是自己加入的,和 ecdsa 本身並沒有任何關係。校驗碼也是自己加上去的而已。我們可以看一下下面的圖片.**

有一段時間我在分析 java 的 ECKey 的程式碼發現 java 底層的橢圓曲線演算法的實現,這裡我就不做更多的說明了。 關鍵是我們如何實現分層確定性錢包,這個很簡單也很複雜,其實就是找私鑰 \(G\) ,至於這個 \(G\) 怎麼找,我們可以檢視精通比特幣裡面的說明,這裡面只是提到了 HMAC-SHA512。看來這裡面隱藏了很多的細節因素,我們有時間需要研究一下,HMAC-SHA512 的知識了。
# 標籤
Cypherpunks Taiwan
密碼學使自由和隱私再次偉大。Cryptography makes freedom and privacy great again.