挖礦和共識
概述
"挖礦"一詞是有一些誤導性的。通過類比貴金屬的提取,它將我們的注意力集中在挖礦的獎勵上,這是每個區塊創建的新比特幣。儘管這種獎勵激勵了挖礦,但挖礦的主要目的不是獎勵或生成新的硬幣。如果你僅將挖礦看作是創建比特幣的過程,那麼你就錯誤地將手段(激勵)當成了過程的目標。挖礦是支撐去中心化清算所的機制,使交易得到驗證和清算。挖礦是使比特幣特別的發明,是一種去中心化的安全機制,是P2P數字現金的基礎。
新鑄造的硬幣和交易費用獎勵是一種激勵計劃,它將礦工的行為與網路的安全保持一致,同時實施貨幣供應。
|
Tip
|
挖礦的目的不是創造新的比特幣。這是激勵機制。挖礦是使比特幣的 安全性 security 去中心化 decentralized的機制。 |
礦工確認新的交易並將其記錄在全球總賬中。包含自上一個區塊以來發生的交易的新區塊,平均每10分鐘被"挖出",從而將這些交易添加到區塊鏈中。成為區塊的一部分並添加到區塊鏈中的交易被認為是"確認"的,這允許比特幣的新的所有者花費他們在這些交易中收到的比特幣。
為礦工獲得兩種類型的獎勵以換取挖礦提供的安全性:每個新區塊創建的新幣以及該區塊中包含的所有交易的交易費用。為了獲得這種獎勵,礦工們競相解決基於密碼雜湊演算法的數學難題。這個難題的解決方案被稱為工作證明(Proof-of-Work),它被包含在新的區塊中,作為礦工大量計算工作的證據。解決PoW演算法贏得獎勵以及在區塊鏈上記錄交易的權利的競爭是比特幣安全模型的基礎。
這個過程稱為挖礦,因為獎勵(新硬幣的產生)旨在模擬像開採貴金屬一樣的收益遞減。比特幣的貨幣供應是通過挖礦創造的,類似於央行通過打印鈔票發行新貨幣的方式。大約每四年(或正好每210,000區塊),一個礦工可以添加到區塊的最大新增比特幣數量減少一半。2009年1月開始每個區塊50比特幣,2012年11月每個區塊減半到25比特幣,2016年7月再次減少到12.5比特幣。基於這個公式,比特幣挖礦獎勵指數級下降,到2140年左右,所有的比特幣(兩千一百萬)將發行完畢。2140年以後,不會有新的比特幣發行。
比特幣礦工也從交易中賺取費用。每筆交易都可能包含一筆交易費用,費用以交易的輸入與輸出之間的盈餘形式體現。獲勝的比特幣礦工可以對包含在獲獎區塊中的交易"零錢"。今天,這筆費用佔比特幣礦工收入的0.5%或更少,絕大多數來自新鑄造的比特幣。然而,獎勵隨著時間推移而減少,每個區塊的交易數量逐漸增加,比特幣開採收入的更大比例將來自費用。逐漸地,挖礦獎勵將由交易費取代,成為礦工的主要動機。2140年以後,每個區塊的新比特幣數量將降至零,比特幣開採將僅通過交易費用獲得激勵。
在本章中,我們首先將挖礦視為貨幣供應機制進行研究,然後研究挖礦最重要的功能:支援比特幣安全性的分散式共識機制。
要理解挖礦和共識,我們會跟蹤Alice的交易,它被Jing的挖礦設備接收並添加到一個區塊。然後我們將跟蹤這個區塊,它被挖出並添加到區塊鏈,然後通過自發共識(emergent consensus)的過程被比特幣網路接受。
比特幣經濟學和貨幣創造
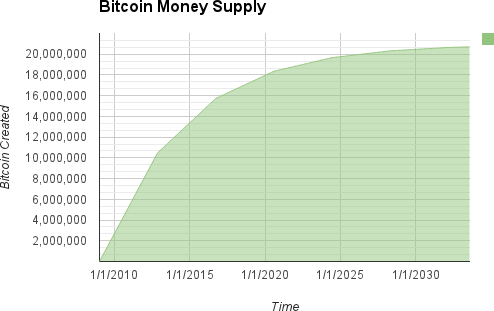
比特幣在創建每個區塊時以固定和遞減的速度被"鑄造"。平均每10分鐘產生一個包含全新的比特幣的區塊,憑空產生。每隔21萬個區塊,或大約每四年,貨幣發行速率就會下降50%。在網路運轉的前四年,每個區塊包含50個新的比特幣。
2012年11月,比特幣發行速率降至每區塊25比特幣。2016年7月,再次下降到每區塊12.5比特幣。它將在630,000區塊區塊再次減半至6.25比特幣,這將是2020年的某個時間。新硬幣的比率將按照指數規律進行32次"減半",直到6,720,000區塊(大約在2137年開採),達到最低貨幣單位,1 satoshi。大約2140年之後,將有690萬個區塊,發行近2,099,999,997,690,000個satoshis,即將近2100萬比特幣。此後,區塊將不包含新的比特幣,礦工將僅通過交易費獲得獎勵。 Supply of bitcoin currency over time based on a geometrically decreasing issuance rate 展示了隨時間推移流通的比特幣總量,貨幣發行量下降。
Figure 1. Supply of bitcoin currency over time based on a geometrically decreasing issuance rate
|
Note
|
開採的最大硬幣數量是比特幣可能的挖礦獎勵的上限。實際上,礦工可能會故意挖一個獲得的獎勵少於全部獎勵的區塊。已經有這樣的區塊,之後可能更多,這將導致貨幣供應量的減少。 |
在 A script for calculating how much total bitcoin will be issued 的示例程式碼中,我們計算比特幣的發行總量。
Example 1. A script for calculating how much total bitcoin will be issued
link:code/max_money.py[]Running the max_money.py script 展示了運行腳本的結果
Example 2. Running the max_money.py script
$ python max_money.py
Total BTC to ever be created: 2099999997690000 Satoshis有限和遞減的發行,保證了固定的貨幣供應量,可以抵制通貨膨脹。不同於法定貨幣中央銀行的無限印錢,比特幣永遠不會因印錢而膨脹。
去中心化共識(Decentralized Consensus)
在上一章中,我們考察了區塊鏈,即所有交易的全球公共賬本(列表),比特幣網路中的每個人都認可它作為所有權的權威記錄。
但是,網路中的每個人怎麼能夠就一個普遍的"真相"達成一致:誰擁有什麼,而不必相信任何人呢?所有傳統的支付系統都依賴於信託模式,該模式具有提供清算所服務的中央機構,驗證和清算所有交易。比特幣沒有中央權威機構,但每個完整的節點都有一個可以信任的權威記錄的公共賬本的完整副本。區塊鏈不是由中央機構創建的,而是由網路中的每個節點獨立組裝。而且,網路中的每個節點都會根據通過不安全的網路連接傳輸的訊息,得出相同的結論,並與其他人一樣收集相同的公共賬本。本章將探討比特幣網路在沒有中央權威機構的情況下達成全球共識的過程。
中本聰的主要發明是 自發共識 的去中心化機制。自發,是因為共識不是明確地達成的,達成共識時沒有選舉或固定的時刻。相反,共識是數千個遵循簡單規則的獨立節點,異步交互的自發性產物。 比特幣的所有屬性,包括貨幣,交易,支付,以及不依賴中央機構或信任的安全模型,都源自於這項發明。
比特幣的去中心化共識來自四個獨立於網路節點的過程的相互作用:
-
每筆交易由完整節點獨立驗證,基於一份全面的標準清單
-
通過挖礦節點將交易獨立地聚合到新的區塊中,並通過PoW演算法證明計算。
-
每個節點獨立驗證新的區塊,並組裝到區塊鏈中
-
通過工作流程證明,每個節點獨立選擇具有最多累積計算量證明的鏈
在接下來的幾節中,我們將研究這些流程以及它們如何相互作用創建網路共識的自發性,以允許任何比特幣節點組裝自己的權威的、信任的、公共的全局賬本的副本。
獨立交易驗證
在 [transactions] 中, 我們看到了錢包軟體如何通過收集UTXO創建交易,提供適當的解鎖腳本,然後構建分配給新所有者的新輸出。然後將產生的交易發送到比特幣網路中的相鄰節點,以便它可以在整個比特幣網路上傳播。
但是,在向鄰居轉發交易之前,接收交易的每個比特幣節點都將首先驗證交易。確保只有有效的交易通過網路傳播,無效的交易會被遇到它們的第一個節點丟棄。
每個節點根據一個很長的標準檢查清單驗證每筆交易:
-
交易的語法和資料結構必須正確
-
輸入和輸出列表都不為空
-
所有交易的位元組大小小於 MAX_BLOCK_SIZE.
-
每個輸出值,和總的輸出值,都必須在允許的範圍區間(小於2100萬比特幣,大於 dust 閾值)
-
任何輸入的hash不等於0,N不等於-1 (幣基交易不應該被傳播)
-
nLocktime 等於 INT_MAX, 或者 nLocktime 和 nSequence 的值滿足 MedianTimePast 的要求
-
每筆交易的位元組大小大於或等於 100
-
交易中包含的簽名操作(SIGOPS) 小於簽名操作限制
-
解鎖腳本( scriptSig )只能向堆疊中壓入數值, 鎖定腳本 (scriptPubkey) 必須匹配 IsStandard 格式 (拒絕非標準的交易).
-
交易池或主分支的一個區塊中必須存在這筆交易
-
對於每個輸入,如果引用的輸出存在於池中的任意一筆其他交易中,則這筆交易被拒絕
-
對於每個輸入,查找主分支和交易池以找到引用的輸出的交易。如果任何輸入的輸出交易丟失,這將成為一筆孤兒交易。如果匹配的交易沒在池中,添加它到孤兒交易池
-
對於每個輸入,如果引用的交易是幣基輸出,它必須有至少 COINBASE_MATURITY (100) 次確認
-
對於每個輸入,引用的輸出必須存在且未被花費
-
使用引用的輸出交易來獲得輸入值,檢查每個輸入值,以及總和,在允許的範圍中(大於0,小於2100萬).
-
如果輸入值的總和小於輸出值的總和,拒絕
-
如果交易費太低( minRelayTxFee ),拒絕
-
每個輸入的解鎖腳本必須與對應的輸出的鎖定腳本匹配
這些條件的詳情可以在 Bitcoin Core 中的 AcceptToMemoryPool, CheckTransaction, 和 CheckInputs 中看到。注意,條件是隨時間改變的,以應對新的拒絕服務攻擊類型,或者放鬆規則以包含更多類型的交易。
通過在交易到達後,向外傳播前,獨立驗證,每個節點都簡歷了一個有效(但未確認)的交易池,稱為 transaction pool,memory pool 或 mempool。
挖礦節點
Jing,上海的電腦工程學生,是一個比特幣礦工。Jing通過運營一個"鑽井平臺"來獲得比特幣,這是針對比特幣設計的專業電腦硬體系統。Jing的這套專業系統連接到一個完整比特幣節點伺服器。和 Jing 的做法不同,一些礦工在沒有完整節點的情況下挖礦,我們將在 礦池 中看到。和每個完整節點一樣,Jing的節點在比特幣網路上接收和傳播未確認的交易,也將這些交易聚合到新的區塊中。
Jing的節點和所有節點一樣,監聽在比特幣網路上傳播的新區塊。但是,新區塊的出現對挖礦節點有特殊的意義。礦工之間的競爭實際上以一個新的區塊的傳播而結束,這個區塊的作用是宣佈一個贏家。對礦工來說,得到一個有效的新區塊意味著其他人贏得了競爭,而他們輸了。然而,一輪比賽的結束也是下一輪比賽的開始。新的區塊不只是一個方格旗,標誌著比賽的結束;它也是下一個區塊競賽的發令槍。
將交易聚合到區塊中
在驗證交易之後,比特幣節點將把它們添加到 memory pool 或 transaction pool 中,在那裡等待交易被包含(挖)到一個區塊中。Jing的節點收集、驗證和轉發新的交易,就像其他節點一樣。然而,與其他節點不同的是,Jing的節點將這些交易聚合到 candidate block 中。
我們來看看Alice在Bob’s Cafe買咖啡時創建的區塊(見 [cup_of_coffee] )。Alice的交易包含在277,316區塊中。為了演示本章的概念,讓我們假設該區塊是由Jing的挖礦系統挖的,並跟蹤Alice的交易,是如何成為這個新區塊的一部分的。
Jing的挖礦節點維護區塊鏈的本地副本。當Alice買咖啡的時候,Jing的節點已經裝配了一個鏈到277,314。Jing的節點監聽交易,試圖挖一個新區塊,也監聽其他節點發現的區塊。當Jing的節點在挖礦時,它通過比特幣網路接收到區塊 277315。這個區塊的到來標誌著第277315區塊競賽的結束,以及第277316區塊競賽的開始。
在之前的10分鐘裡,Jing的節點搜索277,315區塊的解決方案時,它也在收集交易,併為下一個區塊做準備。到目前為止,它已經在Memory pool中收集了幾百個交易。在接收到第277315區塊並進行驗證之後,Jing的節點還將它與Memory pool中的所有交易進行比較,並刪除第277315區塊中包含的任何交易。留在Memory pool中的交易都是未確認的,並等待在新的區塊中記錄。
Jing的節點立即構造一個新的空區塊,作為277,316區塊的候選。這個區塊被稱為 candidate block ,因為它還不是一個有效的區塊,不包含有效的工作證明。只有當礦機成功找到PoW的解決方案時,該區塊才有效。
當Jing的節點將Memory pool中的所有交易彙總時,新的候選區塊有418筆交易,總交易費用為0.09094928比特幣。你可以使用Bitcoin Core客戶端命令行介面在區塊鏈中看到這個區塊,如 Using the command line to retrieve block 277,316 所示。
Example 3. Using the command line to retrieve block 277,316
$ bitcoin-cli getblockhash 277316
0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4
$ bitcoin-cli getblock 0000000000000001b6b9a13b095e96db41c4a928b97ef2d9\
44a9b31b2cc7bdc4{
"hash" : "0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4",
"confirmations" : 35561,
"size" : 218629,
"height" : 277316,
"version" : 2,
"merkleroot" : "c91c008c26e50763e9f548bb8b2fc323735f73577effbc55502c51eb4cc7cf2e",
"tx" : [
"d5ada064c6417ca25c4308bd158c34b77e1c0eca2a73cda16c737e7424afba2f",
"b268b45c59b39d759614757718b9918caf0ba9d97c56f3b91956ff877c503fbe",
... 417 more transactions ...
],
"time" : 1388185914,
"nonce" : 924591752,
"bits" : "1903a30c",
"difficulty" : 1180923195.25802612,
"chainwork" : "000000000000000000000000000000000000000000000934695e92aaf53afa1a",
"previousblockhash" : "0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569"
}幣基交易
區塊中的第一筆交易是一筆特殊的交易,叫做 幣基交易 coinbase transaction。這筆交易是 Jing 的節點創建的,包含對他的挖礦努力的獎勵。
|
Note
|
當區塊 277,316 被挖出時,獎勵是每個區塊25比特幣。在其之後,一個"減半"週期已經過去。區塊獎勵在2016年7月變為12.5比特幣。2020年,到達210000區塊時,將再次減半。 |
Jing的節點創建了coinbase交易,對自己錢包的支付:"支付給Jing的地址25.09094928比特幣"。Jing開採一個區塊所收取的獎勵總額是幣基獎勵(25個新比特幣)和該區塊所有交易的費用(0.09094928)之和,如 Coinbase transaction 所示。
Example 4. Coinbase transaction
$ bitcoin-cli getrawtransaction d5ada064c6417ca25c4308bd158c34b77e1c0eca2a73cda16c737e7424afba2f 1
{
"hex" : "01000000010000000000000000000000000000000000000000000000000000000000000000ffffffff0f03443b0403858402062f503253482fffffffff0110c08d9500000000232102aa970c592640d19de03ff6f329d6fd2eecb023263b9ba5d1b81c29b523da8b21ac00000000",
"txid" : "d5ada064c6417ca25c4308bd158c34b77e1c0eca2a73cda16c737e7424afba2f",
"version" : 1,
"locktime" : 0,
"vin" : [
{
"coinbase" : "03443b0403858402062f503253482f",
"sequence" : 4294967295
}
],
"vout" : [
{
"value" : 25.09094928,
"n" : 0,
"scriptPubKey" : {
"asm" : "02aa970c592640d19de03ff6f329d6fd2eecb023263b9ba5d1b81c29b523da8b21OP_CHECKSIG",
"hex" : "2102aa970c592640d19de03ff6f329d6fd2eecb023263b9ba5d1b81c29b523da8b21ac",
"reqSigs" : 1,
"type" : "pubkey",
"addresses" : [
"1MxTkeEP2PmHSMze5tUZ1hAV3YTKu2Gh1N"
]
}
}
]
}與一般交易不同,幣基交易不消耗(花費)UTXO作為輸入。它只有一個輸入,叫做 coinbase 幣基,從無創造比特幣。幣基交易有一筆輸出,可支付給礦工自己的比特幣地址。幣基交易的輸出將 25.09094928 比特幣發送到礦工的比特幣地址;在這個例子中,是:1MxTkeEP2PmHSMze5tUZ1hAV3YTKu2Gh1N.
幣基獎勵和費用
為了創建幣基交易,Jing的節點首先通過累計418筆交易的輸入和輸出計算所有交易費用。計算方式如下:
Total Fees = Sum(Inputs) - Sum(Outputs)
在區塊 277,316 中,總的交易費用為 0.09094928 比特幣。
接下來,Jing的節點計算新區塊的正確獎勵。獎勵是根據區塊的高度來計算的,從每區塊50比特幣開始,每21萬個區塊減少一半。因為這個方區塊的高度是277,316,正確的獎勵是25比特幣。
在 Bitcoin Core 客戶端的 GetBlockSubsidy 方法中可以看到,如 Calculating the block reward —— Function GetBlockSubsidy, Bitcoin Core Client, main.cpp 所示:
Example 5. Calculating the block reward —— Function GetBlockSubsidy, Bitcoin Core Client, main.cpp
CAmount GetBlockSubsidy(int nHeight, const Consensus::Params& consensusParams)
{
int halvings = nHeight / consensusParams.nSubsidyHalvingInterval;
// Force block reward to zero when right shift is undefined.
if (halvings >= 64)
return 0;
CAmount nSubsidy = 50 * COIN;
// Subsidy is cut in half every 210,000 blocks which will occur approximately every 4 years.
nSubsidy >>= halvings;
return nSubsidy;
}最初的獎勵以 聰(satoshis)為單位,通過50乘以 COIN 常數(100,000,000聰)。這將初始獎勵設置為 50億 satoshis。
然後,方法計算 halvings (減半)的次數,當前區塊高度除減半區間( SubsidyHalvingInterval ),在這個例子中,是 277,316 / 210,000,結果為1。
最大的減半次數為 64,所以如果超過 64 次減半,程式碼返回 0 (只獎勵費用)獎勵。
接下來,該函數使用二進制右移運算符將獎勵( nSubsidy )分為兩半。在277,316區塊的情況下,對50億 satoshis 的獎勵進行二元右移(一次減半),結果為 25億 satoshis 或25個比特幣。使用二進制右移運算符是因為它比多次除法更有效率。為了避免潛在的錯誤,位移操作在63次減半後跳過,補貼設置為0。
最後,幣基獎勵 (nSubsidy) 被加到交易費上 (nFees), 返回總和。
|
Tip
|
如果Jing的挖礦節點寫出了coinbase交易,那麼Jing是不是可以"獎勵"他自己的100或1000比特幣?答案是,錯誤的獎勵會導致該區塊被其他人認為是無效的,從而浪費了Jing用於工作證明的電力。只有該區塊被大家接受,Jing才能花費獎勵。 |
幣基交易的結構
通過這些計算,Jing的節點通過支付其自己 25.09094928 比特幣構建幣基交易。
如你在 Coinbase transaction 中看到, 幣基交易有特殊的格式。不同於指定一個要花費的之前的UTXO的交易輸入,它有一個 "coinbase" 輸入。我們在 [tx_in_stracture] 中檢查交易輸入。讓我們比較一下普通交易輸入和幣基交易輸入。The structure of a "normal" transaction input 展示了普通交易輸入的結構,The structure of a coinbase transaction input 展示了幣基交易輸入的結構。
| Size | Field | Description |
|---|---|---|
32 bytes |
交易的Hash |
指向包含要花費的UTXO的交易的指針 |
4 bytes |
輸出的索引 |
要花費的UTXO的索引號,第一個從0開始 |
1-9 bytes (VarInt) |
解鎖腳本大小 |
接下來的解鎖腳本的長度(位元組) |
Variable |
解鎖腳本 |
滿足UTXO鎖定腳本條件的腳本 |
4 bytes |
序列號 |
目前禁用的 Tx-replacement 功能, 設置為 0xFFFFFFFF |
| Size | Field | Description |
|---|---|---|
32 bytes |
交易的Hash |
所有位都是0:沒有要引用的交易 |
4 bytes |
輸出的索引 |
所有位都是1: 0xFFFFFFFF |
1-9 bytes (VarInt) |
幣基數據大小 |
幣基數據的長度,2 到 100 位元組 |
Variable |
幣基數據 |
用於額外隨機數和挖礦標籤的任意數據。在v2區塊中,必須從區塊高開始 |
4 bytes |
序列號 |
設為 0xFFFFFFFF |
在幣基交易中,前兩個欄位被設置為不引用UTXO的值。不同於"交易的Hash",第一個欄位填充32個字節,全部設置為零。 "輸出索引" 填充4個字節,全部設置為0xFF(十進制255)。"解鎖腳本"( scriptSig )被幣基數據(Coinbase Data)取代,這是礦工使用的數據欄位,我們將在下面看到。
幣基數據 Coinbase Data
幣基交易沒有解鎖腳本( scriptSig )欄位。這個欄位被 coinbase data 替代,該欄位必須包含 2-100 個位元組。除了前幾個位元組,其他的可由礦工填充任意數據。
例如,中本聰在創世區塊的 coinbase data 中加入了文本 "The Times 03/Jan/2009 Chancellor on brink of second bailout for banks", 將它作為日期的證明,並傳達了一個訊息. 現在,礦工使用 coinbase data 存放額外的隨機值,和識別礦池的字串。
幣基的前幾個位元組以前是隨機的,但現在不是了。根據BIP-34,version-2區塊(版本號為2)必須在幣基交易欄位的開頭包含區塊高度作為腳本 push 操作。
在區塊 277,316 中我們看到的幣基( 參見 Coinbase transaction ),位於交易輸入的解鎖腳本或 scriptSig 欄位,包含十六進制值 03443b0403858402062f503253482f。讓我們解碼它。
第一個位元組 03 指示腳本執行引擎將接下來的三個位元組壓入腳本堆疊(參見 [tx_script_ops_table_pushdata] )。接下來的三個位元組,0x443b04,是用小端序編碼的區塊高度(倒序,低位位元組優先)。反轉位元組的順序,結果是 0x043b44 ,十進制是277,316。
接下來的幾個十六進制數據(0385840206),編碼了額外的隨機數(參見 額外隨機數解決方案),用於找到PoW的解決方案。
幣基數據的最後部分( 2f503253482f )是ASCII編碼的字串 /P2SH/,表明挖到這個區塊的節點支援 BIP-16 中定義的 P2SH 交易。P2SH 能力的引入要求礦工認可BIP-16或BIP-17。支援BIP-16的人將在他們的coinbase數據中包含 /P2SH/。支援P2SH的BIP-17實現的人將字串 p2sh/CHV 包含在他們的coinbase數據中。BIP-16勝出,許多礦工繼續在他們的coinbase中包含字串 /P2SH/ ,以表示對該特性的支援。
Extract the coinbase data from the genesis block 使用 [alt_libraries] 中介紹的 libbitcoin 庫從創世區塊中提取幣基數據,展示中本聰的訊息。注意,libbitcoin 庫包含一份創世區塊的靜態副本,所以示例程式碼可以直接從庫中檢索到創世區塊。
Example 6. Extract the coinbase data from the genesis block
link:code/satoshi-words.cpp[]我們使用 GNU C++ 編譯器編譯和運行:
Example 7. Compiling and running the satoshi-words example code
$ # Compile the code
$ g++ -o satoshi-words satoshi-words.cpp $(pkg-config --cflags --libs libbitcoin)
$ # Run the executable
$ ./satoshi-words
The Times 03/Jan/2009 Chancellor on brink of second bailout for banks構建區塊頭
要構建區塊頭,挖礦節點需要填充6個欄位,在 The structure of the block header 列出:
| Size | Field | Description |
|---|---|---|
4 bytes |
Version |
最終軟體/協議更新的版本號 |
32 bytes |
Previous Block Hash |
引用鏈中上一個區塊(父區塊)的雜湊值 |
32 bytes |
Merkle Root |
該區塊中交易的merkle樹的根Hash |
4 bytes |
Timestamp |
區塊的大概創建時間( Unix 紀元以來的秒數 ) |
4 bytes |
Target |
該區塊的 PoW 演算法目標 |
4 bytes |
Nonce |
PoW 演算法使用的計數器 |
在 277,316 區塊被挖出時,區塊結構的版本號是2,以小端序編碼為四位元組是 0x02000000.
接下來,挖礦節點需要添加 "Previous Block Hash" ( 稱為 prevHash )。這是 277,315 區塊的雜湊值,是 Jing 的節點從網路收到並接受的作為候選區塊 277,316 的父區塊。277,315 區塊的雜湊值是:
0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569
|
Tip
|
通過選擇特定的父區塊(由候選區塊頭中的 Previous Block Hash 欄位所指示),Jing將其挖礦能力用於擴展以該特定區塊結束的鏈。從本質上說,這就是 Jing 使用他的挖礦力量為最長難度的有效鏈"投票"。 |
下一步是使用merkle樹彙總所有交易,以便將merkle根添加到區塊頭中。coinbase交易被列為區塊中的第一個交易。然後,在它之後又添加了418個交易,總共在區塊中添加了419個交易。如我們在 [merkle_trees] 中看到的,樹中必須有偶數個"葉子"節點,因此最後一個交易被複制,創建420個節點,每個節點都包含一個交易的雜湊。然後將交易雜湊成對地組合在一起,創建樹的每一級,直到將所有交易彙總為樹的"根"節點。merkle樹的根將所有交易彙總為單個32字節的值,你可以看到 Using the command line to retrieve block 277,316 中列出的"merkle root":
c91c008c26e50763e9f548bb8b2fc323735f73577effbc55502c51eb4cc7cf2e
Jing 的挖礦節點然後將添加 4位元組的時間戳,編碼為 Unix 紀元時間戳,表示從 UTC/GMT時間 1970年1月1日 零點 以來的秒數,1388185914 等於 Friday, 27 Dec 2013, 23:11:54 UTC/GMT。
然後 Jing 的節點填充 目標(target)欄位,定義了使其成為一個有效區塊所需的PoW。target 在區塊中以 "target bits" 矩陣儲存,這是目標的 尾數-指數(mantissa-exponent)編碼。編碼有1位元組的指數,緊接3位元組的尾數(係數)。例如,在區塊 277,316 中,target bits 的值是 0x1903a30c。第一部分 0x19 是一個十六進制指數,後面的部分,0x03a30c,是係數。target 的概念和 target bits 的表示分別在 重新設定目標調整難度 和 目標(Target)的表示 中說明。
最後一個欄位是隨機數(nonce),初始化為0。
隨著所有其他欄位被填充,區塊頭現在已經完成,挖礦過程開始。目標是找到一個隨機數的值,使區塊頭的雜湊值小於 target。在找到合適的隨機值前,挖礦節點可能需要嘗試數十億,或數萬億次。
挖出區塊
用最簡單的術語來說,挖礦是重複雜湊區塊頭的過程,不斷更改參數,直到生成的雜湊值與特定目標相匹配。雜湊函數的結果不能預先確定,也不能創建產生特定雜湊值的模式。雜湊函數的這種特性意味著產生匹配特定目標的雜湊結果的唯一方法是反覆嘗試,隨機修改輸入,直到偶然出現所需的結果。
工作量證明演算法 Proof-of-Work Algorithm
密碼雜湊演算法的關鍵特徵是,在計算上不可能找到產生相同指紋的兩個不同輸入(稱為 碰撞 collision)。作為推論,除了嘗試隨機輸入之外,通過選擇輸入以產生期望的指紋的方式實際上也是不可能的。
使用SHA256,無論輸入是什麼,輸出總是256位的。在 SHA256 example 中,我們使用Python解釋器計算 "I am Satoshi Nakamoto." 的SHA256雜湊值。
Example 8. SHA256 example
$ pythonPython 2.7.1
>>> import hashlib
>>> print hashlib.sha256("I am Satoshi Nakamoto").hexdigest()
5d7c7ba21cbbcd75d14800b100252d5b428e5b1213d27c385bc141ca6b47989eSHA256 example 展示了 "I am Satoshi Nakamoto" 的雜湊結果:5d7c7ba21cbbcd75d14800b100252d5b428e5b1213d27c385bc141ca6b47989e. 這個 256位的數字是這句話的 雜湊 hash 或 摘要 digest,基於這句話的每部分。添加一個字母、標點符號,或其他任何字元都將產生不一樣的雜湊值。
現在,如果我們改變語句,會會看到完全不同的雜湊值。讓我們使用 SHA256 script for generating many hashes by iterating on a nonce 中簡單的Python腳本嘗試在尾部添加陣列。
Example 9. SHA256 script for generating many hashes by iterating on a nonce
link:code/hash_example.py[]運行它將產生幾個短語的雜湊,通過在文本末尾添加一個數字來使其不同。通過增加數字,我們可以得到不同的雜湊,如 SHA256 output of a script for generating many hashes by iterating on a nonce 所示。
Example 10. SHA256 output of a script for generating many hashes by iterating on a nonce
$ python hash_example.pyI am Satoshi Nakamoto0 => a80a81401765c8eddee25df36728d732... I am Satoshi Nakamoto1 => f7bc9a6304a4647bb41241a677b5345f... I am Satoshi Nakamoto2 => ea758a8134b115298a1583ffb80ae629... I am Satoshi Nakamoto3 => bfa9779618ff072c903d773de30c99bd... I am Satoshi Nakamoto4 => bce8564de9a83c18c31944a66bde992f... I am Satoshi Nakamoto5 => eb362c3cf3479be0a97a20163589038e... I am Satoshi Nakamoto6 => 4a2fd48e3be420d0d28e202360cfbaba... I am Satoshi Nakamoto7 => 790b5a1349a5f2b909bf74d0d166b17a... I am Satoshi Nakamoto8 => 702c45e5b15aa54b625d68dd947f1597... I am Satoshi Nakamoto9 => 7007cf7dd40f5e933cd89fff5b791ff0... I am Satoshi Nakamoto10 => c2f38c81992f4614206a21537bd634a... I am Satoshi Nakamoto11 => 7045da6ed8a914690f087690e1e8d66... I am Satoshi Nakamoto12 => 60f01db30c1a0d4cbce2b4b22e88b9b... I am Satoshi Nakamoto13 => 0ebc56d59a34f5082aaef3d66b37a66... I am Satoshi Nakamoto14 => 27ead1ca85da66981fd9da01a8c6816... I am Satoshi Nakamoto15 => 394809fb809c5f83ce97ab554a2812c... I am Satoshi Nakamoto16 => 8fa4992219df33f50834465d3047429... I am Satoshi Nakamoto17 => dca9b8b4f8d8e1521fa4eaa46f4f0cd... I am Satoshi Nakamoto18 => 9989a401b2a3a318b01e9ca9a22b0f3... I am Satoshi Nakamoto19 => cda56022ecb5b67b2bc93a2d764e75f...
每個短語產生一個完全不同的雜湊結果。它們看起來完全是隨機的,但是你可以在使用Python的任何電腦上再次生成這個示例中的結果,並看到相同的雜湊。
在這種場景中用作變數的數字稱為nonce。nonce用於改變加密函數的輸出,在本例中,是為了改變短語的SHA256指紋。
要對這個演算法提出挑戰,我們來設置一個目標:找到一個短語,它生成一個以0開頭的十六進制雜湊。幸運的是,這並不難! [sha256_example_generator_generator_output] 顯示:"I’m Satoshi Nakamoto13" 這個短語產生的是一個符合我們的標準的雜湊值:0ebc56d59a34f5082aaef3d661696c2b618e6243272169531041a5。花了13次才找到它。在概率方面,如果雜湊函數的輸出是均勻分佈的,我們可以期望每16次找到一個以0開頭的結果(16個十六進制數字0到F中的一個)。在數值方面,這就意味著找到一個雜湊值,小於 0 x1000000000000000000000000000000000000000000000000000000000000000。我們將這個閾值稱為target,目標是找到一個在數值上小於目標的雜湊值。如果我們減少目標,查找小於目標的雜湊值的任務將變得越來越困難。
打個簡單的比方,想象這樣一個遊戲:玩家不斷地擲一副骰子,試圖擲得比指定的目標少。在第一輪,目標是12個。除非你擲雙六,否則你就能贏。下一輪的目標是11。玩家必須投出10或更少的數值才能獲勝。這同樣是一項簡單的任務,假設幾輪之後,目標是5。現在,超過一半的結果將超過目標而無效。隨著目標降低,要想贏得勝利,擲骰子的次數要成倍增加。最終,當目標是2(可能的最小值)時,每36次投擲中只有一次,或其中的2%,會產生一個勝利的結果。
從一個知道骰子游戲的目標是2的觀察者的角度來看,如果有人成功地投出了一個成功的結果,那麼可以假設他們平均嘗試了36次。換句話說,一個人可以從目標設定的難度中估計成功所需要的工作量。當演算法是基於確定性函數(如SHA256)時,輸入本身就構成了 證明 proof,證明做了一定量的 工作 work 才產生低於目標的結果。所以稱為, Proof-of-Work。
|
Tip
|
即使每次嘗試都會產生隨機結果,任何可能結果的概率都可以提前計算。因此,特定難度的結果構成特定工作量的證明。 |
在 SHA256 output of a script for generating many hashes by iterating on a nonce 中, 獲勝的"nonce"是13,這個結果可以被任何人獨立的驗證。任何人都可以在短語"我是中本聰"後面加上數字13,然後計算雜湊,驗證它是否小於目標。成功的結果也是工作的證明,因為它證明我們做了工作去發現那一次。雖然只需要一次雜湊計算就可以驗證,但我們需要13次雜湊計算才能找到一個有效的nonce。如果我們有一個更低的目標(更高的難度),那麼需要更多的雜湊計算才能找到一個合適的nonce,但是對於任何人來說,只有一個雜湊計算需要驗證。此外,通過了解目標,任何人都可以使用統計數據來估計困難程度,從而知道需要做多少工作才能找到這樣一個nonce。
|
Tip
|
PoW必須生成一個小於目標的雜湊值。更高的目標意味著找到低於目標的雜湊值要容易得多。較低的目標意味著更難在目標以下找到雜湊值。目標和難度是反比的。 |
比特幣的PoW與 SHA256 output of a script for generating many hashes by iterating on a nonce 所展示的挑戰非常相似。礦機構造一個充滿交易的候選區塊。接下來,挖礦程序計算這個區塊頭的雜湊,看看它是否小於當前的 target。如果雜湊值不小於目標,那麼礦機將修改nonce(通常只將其遞增1次),並再次嘗試。在比特幣網路目前的難度下,礦工必須嘗試千萬億次,才能找到一個能產生足夠低的區塊頭雜湊的nonce。
一個非常簡單的PoW在 Simplified Proof-of-Work implementation 中以Python實現
Example 11. Simplified Proof-of-Work implementation
link:code/proof-of-work-example.py[]運行這段程式碼,你可以設置所需的難度(以位為單位,有多少位前導位必須為零),並查看電腦需要多長時間才能找到解決方案。在 [pow_example_output] 中,你可以看到它在普通的筆記本上是如何工作的。
Example 12. Running the Proof-of-Work example for various difficulties
$ python proof-of-work-example.py*Difficulty: 1 (0 bits) [...] Difficulty: 8 (3 bits) Starting search... Success with nonce 9 Hash is 1c1c105e65b47142f028a8f93ddf3dabb9260491bc64474738133ce5256cb3c1 Elapsed Time: 0.0004 seconds Hashing Power: 25065 hashes per second Difficulty: 16 (4 bits) Starting search... Success with nonce 25 Hash is 0f7becfd3bcd1a82e06663c97176add89e7cae0268de46f94e7e11bc3863e148 Elapsed Time: 0.0005 seconds Hashing Power: 52507 hashes per second Difficulty: 32 (5 bits) Starting search... Success with nonce 36 Hash is 029ae6e5004302a120630adcbb808452346ab1cf0b94c5189ba8bac1d47e7903 Elapsed Time: 0.0006 seconds Hashing Power: 58164 hashes per second [...] Difficulty: 4194304 (22 bits) Starting search... Success with nonce 1759164 Hash is 0000008bb8f0e731f0496b8e530da984e85fb3cd2bd81882fe8ba3610b6cefc3 Elapsed Time: 13.3201 seconds Hashing Power: 132068 hashes per second Difficulty: 8388608 (23 bits) Starting search... Success with nonce 14214729 Hash is 000001408cf12dbd20fcba6372a223e098d58786c6ff93488a9f74f5df4df0a3 Elapsed Time: 110.1507 seconds Hashing Power: 129048 hashes per second Difficulty: 16777216 (24 bits) Starting search... Success with nonce 24586379 Hash is 0000002c3d6b370fccd699708d1b7cb4a94388595171366b944d68b2acce8b95 Elapsed Time: 195.2991 seconds Hashing Power: 125890 hashes per second [...] Difficulty: 67108864 (26 bits) Starting search... Success with nonce 84561291 Hash is 0000001f0ea21e676b6dde5ad429b9d131a9f2b000802ab2f169cbca22b1e21a Elapsed Time: 665.0949 seconds Hashing Power: 127141 hashes per second
如你所見,將難度增加1位會使找到解決方案所需的時間增加一倍。如果考慮整個256位的數字空間,每次將多一個位限制為0,搜索空間就減少了一半。在 [pow_example_output] 中,需要8400萬次雜湊才能找到一個nonce,它產生的雜湊有26個前導位為零。即使以每秒超過12萬次雜湊的速度,在筆記本上也需要10分鐘才能找到這個解決方案。
在編寫本文時,網路正在嘗試查找一個小於以下值的區塊頭雜湊:
0000000000000000029AB9000000000000000000000000000000000000000000
如你所見,目標的開頭有很多0,這意味著可以接受的雜湊範圍要小得多,很難找到一個有效的雜湊值。網路要發現下一個區塊,平均每秒需要超過1.8 zeta-hashes(thousand billion billion hashes)。這似乎是一項不可能完成的任務,但幸運的是,網路有每秒產生3個exa-hashes(EH/sec)的處理能力,平均10分鐘就能找到一個block。
目標(Target)的表示
在 Using the command line to retrieve block 277,316 中,我們看到這個區塊包含了目標,以一個稱為"target bits"或只是"bits",在區塊277,316中的值為 0x1903a30c。該表示法將工作量證明的驗證目標表示為係數/指數格式,前兩個十六進制數字是指數,後六個十六進制數字是係數。因此,在這個區塊中,指數為 0x19,係數為 0x03a30c。
這種表達方式下計算難度目標的公式是:
- target = coefficient * 2(8*(exponent–3))
使用這個公式,和難度bits值 0x1903a30c,可以得到:
- target = 0x03a30c * 20x08*(0x19-0x03)
- => target = 0x03a30c * 2(0x08*0x16)
- => target = 0x03a30c * 20xB0
十進制就是:
- => target = 238,348 * 2176
- => target =
22,829,202,948,393,929,850,749,706,076,701,368,331,072,452,018,388,575,715,328
轉換為十六進制:
- => target =
0x0000000000000003A30C00000000000000000000000000000000000000000000
這意味著高度為277,316的有效區塊是區塊頭的雜湊值小於目標的區塊。在二進制中,該數字必須有超過60個前導位設置為零。有了這樣的難度,一個礦工每秒處理1萬億次雜湊,平均只能每8,496個區塊或每59天尋找到一次解決方案。
重新設定目標調整難度
正如我們所看到的,目標確定了難度,因此影響了找到工作證明演算法的解決方案所需的時間。這就引出了一個明顯的問題:為什麼困難是可以調整的,由誰來調整,以及如何調整?
比特幣的區塊平均每10分鐘生成一次。這是比特幣的心跳,支撐著貨幣發行的頻率和交易結算的速度。它必須保持不變,不僅是短期的,而是持續幾十年。在這段時間裡,預計電腦的能力將繼續快速增長。此外,參與挖礦的人和電腦的數目也不斷變化。為了保持10分鐘的生成時間,必須考慮這些變化調整挖礦的難度。事實上,工作證明的目標是一個動態參數,它定期調整以滿足10分鐘的區塊間隔目標。簡單地說,可以設置目標值,使當前的挖礦能力導致10分鐘的區塊間隔。
那麼,這種調整是如何在一個完全分散的網路中進行的呢?重新設定目標是獨立地在每個節點上自動進行的。每產生2016個區塊,所有節點都重新設定PoW目標。重新設定目標的公式衡量了找到最後2016個區塊所需的時間,並與預期的20160分鐘(2016個區塊乘以期望的10分鐘區塊間隔)進行了比較。計算實際時間間隔和期望時間間隔的比例,並對目標按比例進行調整(向上或向下)。簡單地說:如果網路發現區塊的速度比每10分鐘快,難度就會增加(目標範圍縮小)。如果區塊發現速度比預期的要慢,那麼難度就會降低(目標範圍增加)。
公式如下:
New Target = Old Target * (Actual Time of Last 2016 Blocks / 20160 minutes)
Retargeting the Proof-of-Work —— CalculateNextWorkRequired() in pow.cpp 展示了 Bitcoin Core 客戶端使用的程式碼。
Example 13. Retargeting the Proof-of-Work —— CalculateNextWorkRequired() in pow.cpp
// Limit adjustment step
int64_t nActualTimespan = pindexLast->GetBlockTime() - nFirstBlockTime;
LogPrintf(" nActualTimespan = %d before bounds\n", nActualTimespan);
if (nActualTimespan < params.nPowTargetTimespan/4)
nActualTimespan = params.nPowTargetTimespan/4;
if (nActualTimespan > params.nPowTargetTimespan*4)
nActualTimespan = params.nPowTargetTimespan*4;
// Retarget
const arith_uint256 bnPowLimit = UintToArith256(params.powLimit);
arith_uint256 bnNew;
arith_uint256 bnOld;
bnNew.SetCompact(pindexLast->nBits);
bnOld = bnNew;
bnNew *= nActualTimespan;
bnNew /= params.nPowTargetTimespan;
if (bnNew > bnPowLimit)
bnNew = bnPowLimit;|
Note
|
目標值的校準每2,016個區塊發生一次,由於原始的Bitcoin Core客戶端中出現了一個差一的錯誤,它是基於之前的2,015個區塊(而不是應該的2,016區塊)的總時間,導致重新設定的目標傾向於難度增加0.05%。 |
Interval (2,016 個區塊) 和 TargetTimespan (兩週時間,1,209,600 seconds) 兩個參數在 chainparams.cpp 中定義.
為了避免難度的極端波動,重新設定目標的調整必須小於每個週期4倍。如果所需的目標調整大於4倍,則調整為4倍而不是更多。任何進一步的調整都將在下一個重新設定目標期間完成,因為這種不平衡將持續到下一個2016個區塊。因此,雜湊算力和難度之間的巨大差異可能需要幾個2,016區塊週期來平衡。
|
Tip
|
挖出比特幣區塊的難度大約需要整個網路"處理10分鐘",根據挖出前2,016個區塊所花費的時間,每2,016個區塊進行一次調整。通過降低或提高目標來實現。 |
請注意,目標與交易的數量或價值無關。這意味著雜湊的算力以及用於保障比特幣安全鎖消耗的電量也完全獨立於交易數量。比特幣可以擴大規模,實現更廣泛的應用,並保持安全,而不需要增加目前的雜湊算力水平。隨著新礦工進入市場競爭獎勵,雜湊算力的增加代表市場的力量。只要足夠的雜湊算力在礦工誠實追求獎勵的控制下進行,就足以防止"接管"攻擊,因此足以保證比特幣的安全。
挖礦的難度與電力成本相關,以及比特幣與用於支付電力的貨幣的匯率。高性能的挖礦系統在當前硅片製造方面儘可能地高效,將電力盡可能高地轉化為雜湊算力。對挖礦市場的主要影響是1千瓦小時的比特幣電價,因為這決定了挖礦的盈利能力,因此影響了進入或退出挖礦市場的選擇。
成功挖到區塊
如我們之前看到的,Jing的節點構建了一個候選區塊,並準備挖它。Jing有幾臺硬體挖礦設備和特定於應用的積體電路,其中幾十萬個積體電路以驚人的速度並行運行SHA256演算法。這些定製的機器通過USB或區網連接到他的挖礦節點。接下來,在Jing的桌面上運行的挖礦節點將區塊頭送到他的挖礦硬體,開始每秒嘗試數萬億隨機數。因為隨機數只有32位,當遍歷完所有可能時(大概40億),挖礦硬體改變區塊頭(調整幣基的隨機數或時間戳)並重新測試隨機數,和新的組合。
開始挖區塊277,316後的大概11分鐘,一個硬體社保發現了結果,並將其發送回挖礦節點。
當插入到區塊頭後,隨機數 924,591,752 產生了以下區塊雜湊值:
0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4
小於目標值:
0000000000000003A30C00000000000000000000000000000000000000000000
Jing的挖礦節點立即將這個區塊發送到它的對等節點。它們接收,驗證,並傳播這個新的區塊。隨著這個區塊在網路上漣漪般傳播,每個節點都將其添加到自己的區塊鏈上,將區塊鏈的高度擴展到 277,316 個區塊。挖礦節點接收並驗證區塊,放棄自己嘗試挖相同區塊的努力,並立即開始計算鏈上的下一個區塊,將Jing的區塊作為"父區塊"。通過在Jing新發現的區塊之上構建,其他的礦工實質上使用它們的算力"投票",認可Jing的區塊和它擴展的區塊。
在下一節,我們將看下每個節點驗證和選擇最長鏈的過程,從而創建了形成去中心化區塊鏈的共識。
驗證新的區塊
比特幣共識機制的第三步是網路中每個節點對每個新區塊進行獨立驗證。隨著新解決的區塊在整個網路中移動,每個節點在傳播給對等節點之前執行一系列測試來驗證它。這確保了只有有效的區塊在網路上傳播。獨立驗證還可以確保那些誠實行動的礦工將自己的區塊整合到區塊鏈中,從而獲得回報。那些不誠實行事的礦工被拒絕,不僅失去了獎勵,而且浪費了尋找工作證明解決方案的努力,導致電力成本沒有補償。
當一個節點收到一個新的區塊時,它將通過一長串檢查清單驗證它必須符合的條件;否則,拒絕該區塊。這些條件可以在 Bitcoin Core 客戶端的方法 CheckBlock 和 CheckBlockHeader 中看到:
-
區塊的資料結構語法正確
-
區塊頭的雜湊值小於目標值
-
區塊的時間戳小於未來2小時(允許時間錯誤)
-
區塊的大小在可接受的限制範圍內
-
第一筆(且只有第一筆)交易是幣基交易
-
區塊中的所有交易是有效的,可以通過 獨立交易驗證 中的驗證
網路上每個節點對每個新區塊的獨立驗證確保礦工不會作弊。在之前的章節中,我們看到礦工如何寫出一筆交易,在該區塊內創建新的比特幣並獲得交易費用。為什麼礦工不會自己寫一千個比特幣的交易,而不是正確的獎勵呢?因為每個節點都根據相同的規則驗證區塊。無效的幣基交易會使整個區塊無效,導致該區塊被拒絕,因此該交易永遠不會成為分類賬的一部分。礦工必須根據所有節點遵循的共同規則構建一個完美的區塊,並通過正確的PoW解決方案來挖它。為此,他們在挖礦中耗費大量的電力,如果他們作弊,所有的電力和精力都被浪費掉了。這就是為什麼獨立驗證是去中心化共識的一個關鍵組成部分。
組裝和選擇區塊的鏈
區塊鏈去中心化共識機制的最後一個步驟是將區塊組裝到鏈中,並選擇最多Proof-of-Work的鏈。當一個節點驗證了一個新的區塊後,它將嘗試通過將區塊鏈接到現有的區塊鏈,來組裝鏈。
節點維護三組區塊:連接到主區塊鏈的區塊,形成主區塊鏈分支的(次級區塊鏈),最後,在已知的鏈中沒有父區塊的區塊(孤兒區塊)。無效的區塊一旦不滿足驗證條件即被拒絕,因此它們不包含在任何鏈中。
任何時候,"主鏈"都是無效鏈區塊中與其相關的最多累積工作量證明。在大多數情況下,這也是其中最多區塊的鏈條,除非有兩條等長鏈和一條有更多的工作量證明。主鏈也將有分支,這些分支是與主鏈上的區塊"兄弟姐妹"。這些區塊是有效的,但不是主鏈的一部分。他們被保留以供將來參考,以防其中一個連鎖店的業務延伸超過主鏈。在下一部分( 區塊鏈分叉 )中,我們將看到由於在同一高度上幾乎同時開採區塊體而出現次級鏈。
"主鏈"在任何時候都是有著最多的累計Proof-of-Work的區塊組成的 有效 鏈。大多數情況下,這也是擁有最多區塊的鏈,除非有兩個高度相同的鏈,其中一個有更多的Proof-of-Work。主鏈會有分支,分支上的區塊時主鏈上區塊的"兄弟姐妹"。這些區塊是有效的但不是主鏈的一部分。它們留作將來引用,以防這些鏈被擴展而超過主鏈。在下一節 區塊鏈分叉 中,我們將看到相同高度的區塊同時被挖而形成的次鏈。
當接收到一個新區塊時,節點將嘗試將其插入到現有的區塊鏈中。節點將查看區塊的"previous block hash"欄位,該欄位是對父區塊的引用。然後,節點將嘗試在現有的區塊鏈中找到父節點。大多數時候,父類將是主鏈的"頂部",意味著這個新區塊擴展了主鏈。例如,新區塊277,316具有對其父區塊277,315的雜湊值的引用。大多數接收277,316的節點都已經有了277,315區塊作為主鏈的頂部,因此將連接新的區塊並擴展該鏈。
有時,正如我們在 [fork] 中看到的,新的區塊擴展了非主鏈的鏈。在這種情況下,節點將把新區塊附加到它所擴展的次級鏈上,然後將次級鏈的 工作量 與主鏈進行比較。如果次級鏈的累積工作量大於主鏈,則節點將在次級鏈上 重新聚合,意味著它將選擇次級鏈作為其新的主鏈,使舊主鏈成為次級鏈。如果節點是一個礦工,那麼它現在將構造一個區塊來擴展這個新的、更長的鏈。
如果一個有效的區塊到達了,但沒有在已有的鏈中找到其父區塊,則這個區塊被認為是"孤兒"。孤兒區塊保存在孤兒區塊池中,直到父區塊到達。一旦父區塊到達並連接到已有的鏈上,孤兒區塊就會被取出,並連接到父區塊上,成為鏈的一部分。孤兒區塊通常在兩個區塊在一段很短的時間內被挖出,但反序到達時發生(子區塊在父區塊之前到達)。
通過選擇最大累積工作量的有效鏈,所有節點最終都能實現網路範圍內的一致。隨著工作量的增加,鏈之間的暫時差異最終得到解決,從而擴展可能鏈中的一條。挖礦節點通過挖下一個區塊來選擇擴展哪個鏈,使用它們的挖礦能力"投票"。當他們挖一個新的區塊並擴展鏈時,新的區塊本身就代表了他們的選票。
在下一節中,我們將討論競爭鏈(分叉)之間的差異是如何通過 最大累積工作量 的鏈的獨立選擇來解決的。
區塊鏈分叉
因為區塊鏈是一個去中心化的資料結構,所以它的不同副本並不總是一致的。區塊可能在不同的時間到達不同的節點,導致節點具有不同的區塊鏈的視圖。為了解決這個問題,每個節點總是選擇並嘗試擴展表示最大工作量證明的區塊的鏈,也稱為最長鏈或最大累計工作量鏈。通過將記錄在鏈中的每個區塊中的工作量相加,節點可以計算創建鏈所花費的總工作量。只要所有節點都選擇最大累積工作量的鏈,全球比特幣網路最終就會收斂到一致的狀態。分叉作為區塊鏈版本之間的臨時不一致而出現,隨著其中一個分叉添加更多區塊時,將最終重新聚合並解決。
|
Tip
|
本節中描述的區塊鏈分叉由於全局網路中的傳輸延遲而自然發生。我們還將在本章後面討論故意誘導的分叉。 |
下面的幾張圖,我們跟蹤網路一個"分叉"事件。這些圖是簡化的比特幣網路表示。為方便說明,不同的區塊以不同的形狀表示。網路中的每個節點表示為圓圈。
每個節點都有自己的全局區塊鏈視角。每個節點從鄰居節點接收區塊,更新自己的區塊鏈副本,選擇最大累計工作量的鏈。為方便說明,每個節點包含一個代表當前主鏈的頂部的形狀。所以,你在節點中看到的星形,表示它是主鏈的頂部。
在第一張圖 Before the fork —— all nodes have the same perspective 中,網路對區塊鏈有統一的視角,星形(star)區塊代表主鏈的頂部。
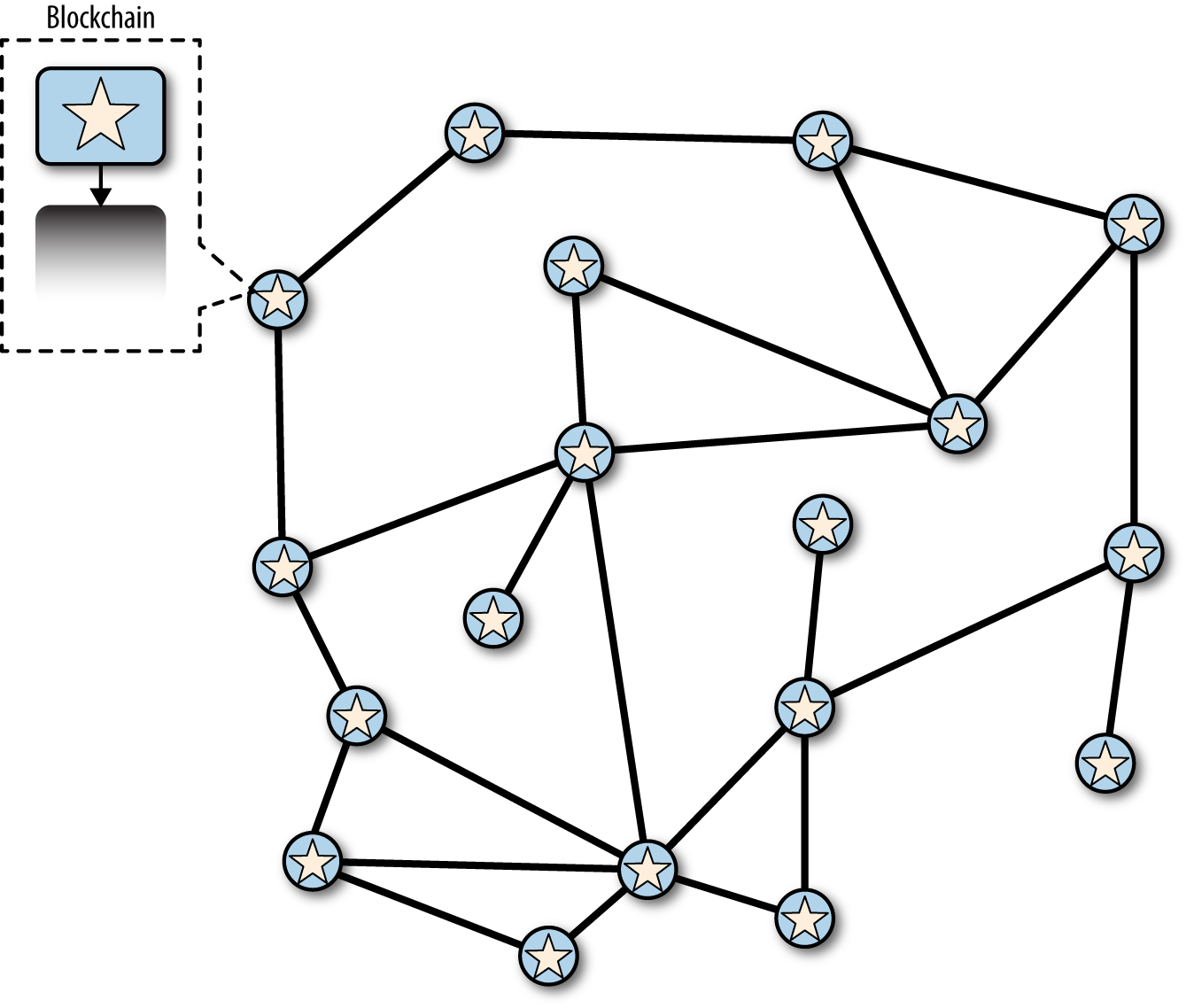
Figure 2. Before the fork —— all nodes have the same perspective
當有兩個候選區塊爭奪形成最長鏈時,發生"分叉"。這通常在兩個礦工在相近的時間段內同時解決了Proof-of-Work演算法。兩個區塊發現它們的候選區塊的解決方案後,立即廣播它們的"獲勝的"區塊給鄰居節點,以使它們在網路上傳播。每個收到有效區塊的節點都將其整合進區塊鏈,將其擴展一個區塊。如果節點之後收到擴展相同父區塊的區塊,則將其視為次級鏈上的候選區塊。結果是,一些節點先看到第一個候選區塊,另一些則先看到第二個,這就形成了區塊鏈的兩個競爭版本。
在 Visualization of a blockchain fork event: two blocks found simultaneously 中,我們看到兩個礦工( 節點X 和 節點Y )幾乎同時挖出了兩個不同的區塊。這兩個區塊都是星形區塊的子區塊,在其之上擴展區塊鏈。為了便於我們追蹤,節點X 產生的標記為三角形(triangle),節點Y產生的標記為倒三角(upside-down triangle)。
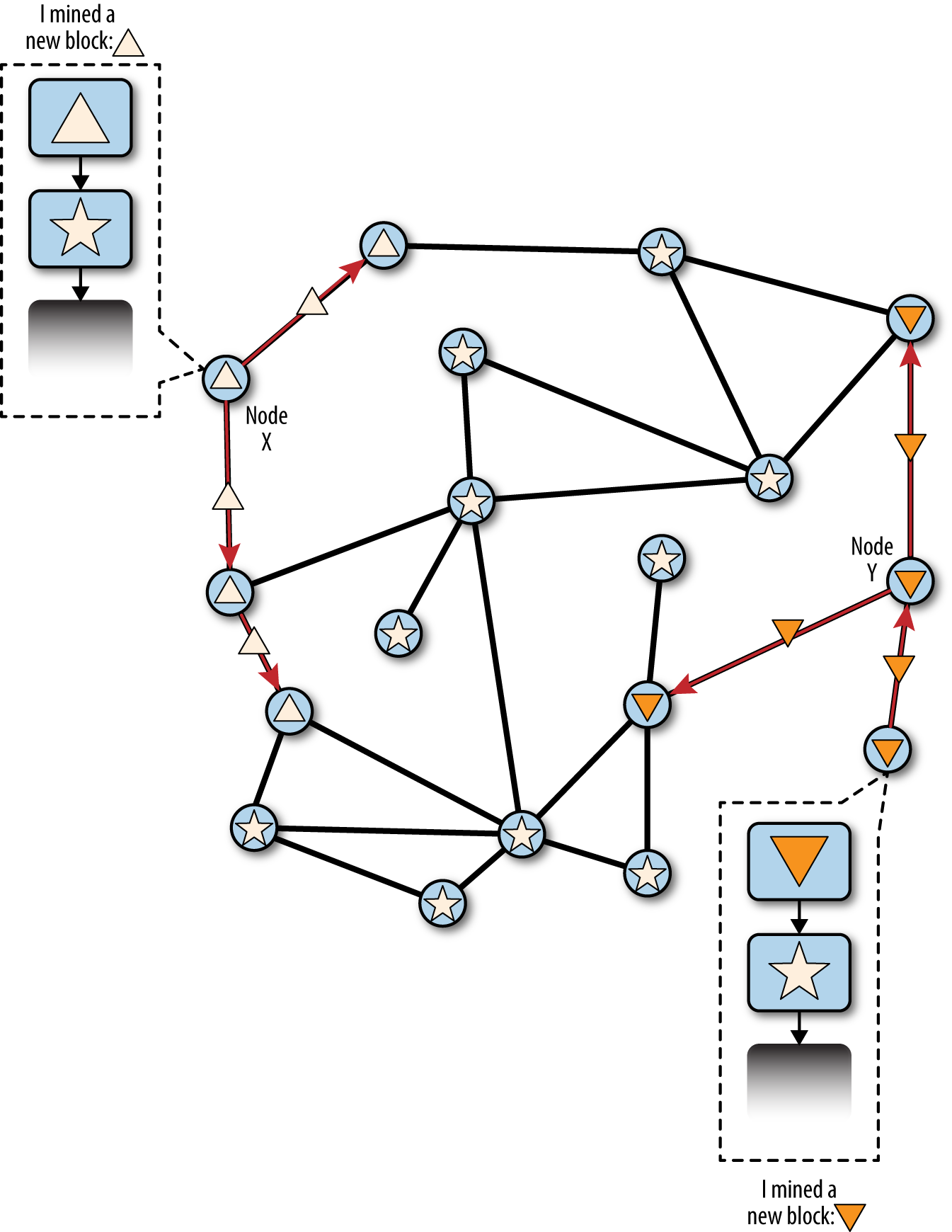
Figure 3. Visualization of a blockchain fork event: two blocks found simultaneously
例如,我們假設節點X為一個擴展區塊鏈的區塊 "triangle" 找到了一個PoW解決方案,構建在父區塊 "star" 之上。幾乎與此同時,同樣從"star"擴展鏈的節點Y找到了區塊 "upside-down triangle" 的解決方案,這是它的候選區塊。兩個區塊都是有效的,兩個區塊都包含一個有效的工作證明解決方案,並且兩個區塊都擴展了相同的父區塊(區塊"star")。這兩個區塊可能包含大部分相同的交易,交易的順序可能只有很少的差異。
當兩個區塊傳播時,一些節點首先接收區塊到"triangle",一些節點首先接收區塊"upside-down triangle"。如 Visualization of a blockchain fork event: two blocks propagate, splitting the network ,網路分割為區塊鏈的兩種不同視角:一邊是 triangle,另一邊是 upside-down triangle 。
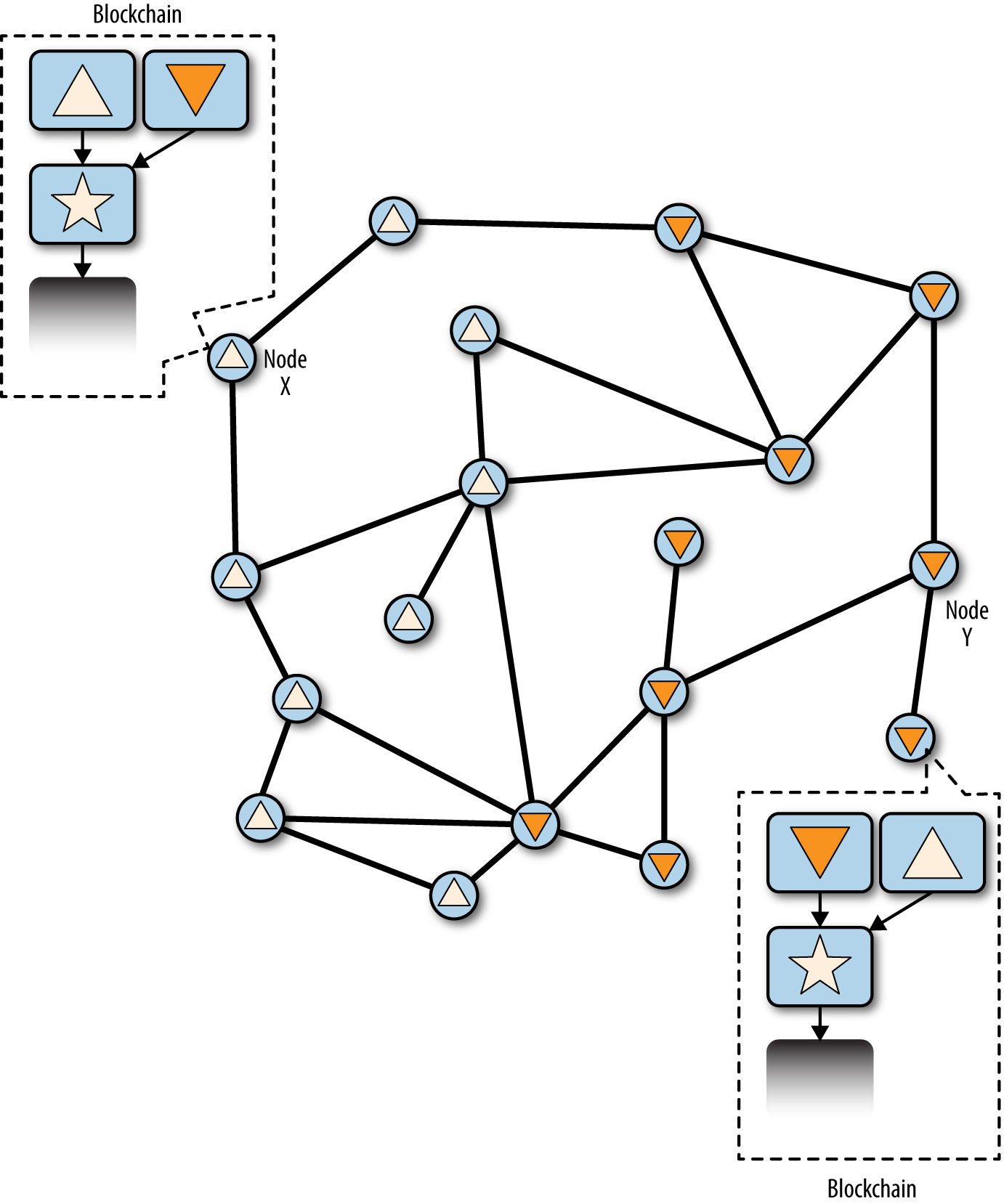
Figure 4. Visualization of a blockchain fork event: two blocks propagate, splitting the network
在圖中,一個隨機選擇的"節點X"首先接收到triangle區塊,並用它擴展star鏈。節點X選擇有"triangle"區塊的鏈作為主鏈。之後,節點X也接收到"upside-down triangle"區塊。由於它是第二名,被認為已經"輸掉"了比賽。然而,"upside-down triangle" 區塊並沒有被丟棄。它與"star"區塊父鏈相連,形成一個次級鏈。雖然節點X假設它已經正確地選擇了獲勝鏈,但它保留了"失敗的"鏈,這樣它就有必要的訊息,如果"失敗的"鏈最終"獲勝",則需要重新聚合。
在網路的另一端,節點Y基於自己對事件序列的看法構建區塊鏈。它首先接受了"upside-down triangle",並選擇了那個鏈條作為"贏家"。當它後來接收到 "triangle" 區塊時,它將它作為一個次級鏈連接到"star"父區塊。
哪一邊都不是"正確的",或者"錯誤的"。兩個都是有效的區塊鏈視角。之後只有一個會勝出,這取決於這兩個相互競爭的鏈如何被後續的工作量擴展。
挖礦視角類似於節點X的節點將立即開始挖一個候選區塊,該區塊以"triangle"作為其頂端擴展鏈。通過將"triangle"鏈接為候選區塊的父元素,它們使用雜湊算力投票。他們的投票支援了他們選出來的主鏈。
挖礦視角類似於節點Y的節點都將開始以"upside-down triangle"為父節點構建候選節點,擴展他們認為是主鏈的鏈。所以,比賽又開始了。
分叉幾乎總是在一個區塊中解決。雖然網路雜湊算力的一部分在"triangle"的頂部構建,而另一部分在"upside-down triangle"的頂部構建。即使雜湊算力幾乎是平均分配的,也很有可能在一組礦工找到任何解決方案之前,另一組礦工可能已經找到解決方案並傳播它。例如,假設在 "triangle" 頂部建造的礦工找到了一個新的區塊"rhombus"(菱形),它擴展了鏈(例如,star-triangle-rhombus)。它們立即傳播這個新區塊,整個網路將其視為有效的解決方案,如 Visualization of a blockchain fork event: a new block extends one fork, reconverging the network 所示。
所有在前一輪中選擇"triangle"作為獲勝者的節點,只需將鏈再延長一個block。然而,選擇"upside-down triangle"作為獲勝者的節點現在將看到兩條鏈:star-triangle-rhombus 和 star-upside-down-triangle。star-triangle-rhombus 鏈現在比其他鏈長(累積工作量更多)。因此,這些節點將 star-triangle-rhombus 鏈作為主鏈,將 star-upside-down-triangle 鏈轉化為二級鏈,如 Visualization of a blockchain fork event: the network reconverges on a new longest chain 所示。這是一個鏈的重新收斂,因為這些節點被迫修改他們對區塊鏈的看法,以納入更長的鏈的新證據。任何致力於將鏈基於 upside-down triangle 進行擴展的礦工現在都會停止工作,因為他們的候選區塊是一個"孤兒",因為它的父區塊"upside-down triangle"不再是最長的鏈。不屬於"triangle"的"upside-down triangle"內的交易被重新插入到mempool中,以便在下一個區塊中包含,從而成為主鏈的一部分。整個網路在一個區塊鏈 star-triangle-rhombus 上重新收斂,"rhombus"是鏈中的最後一個區塊。所有的礦工立即開始在以 "rhombus" 作為父區塊的候選區塊上工作,以擴展 star-triangle-rhombus。
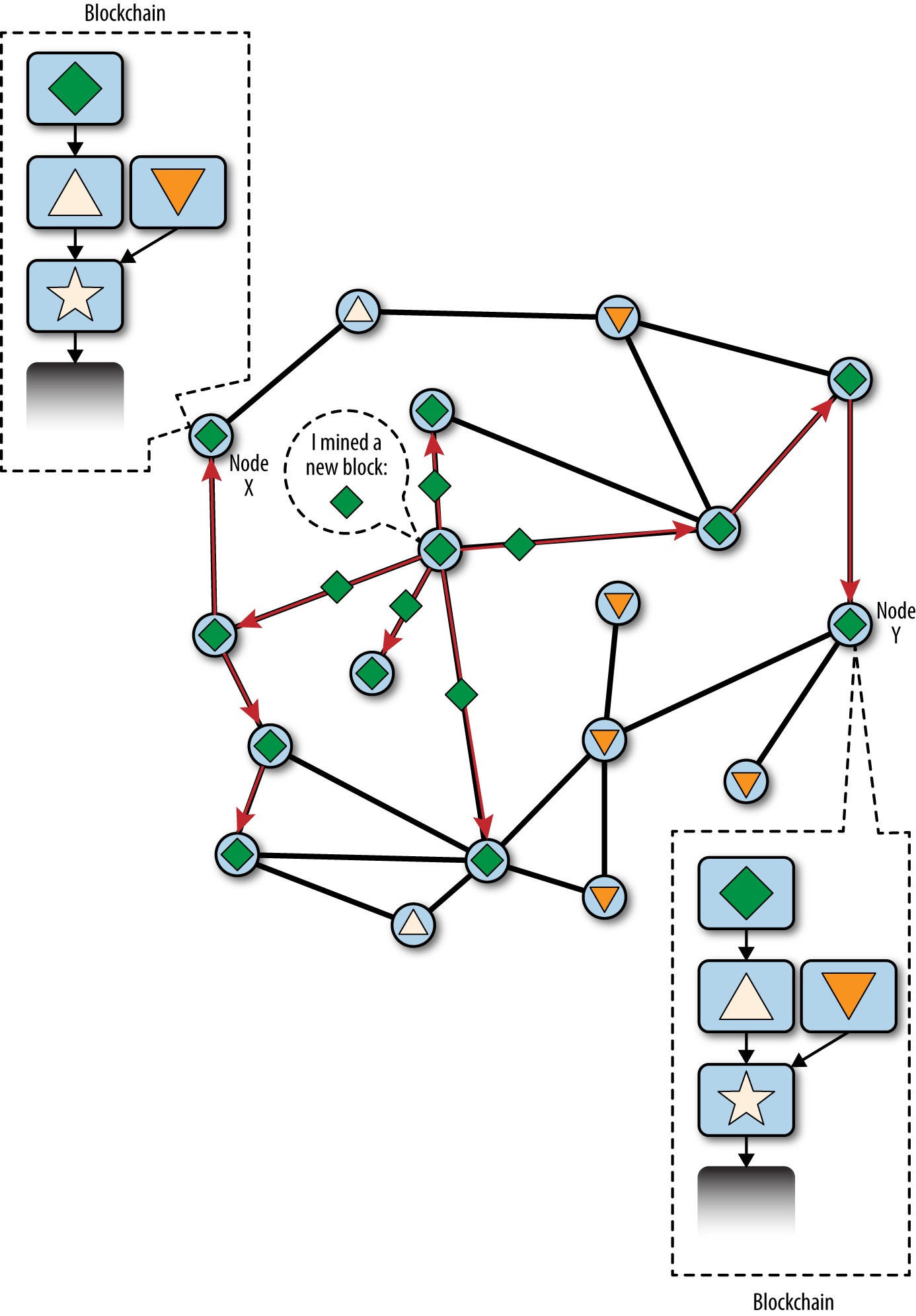
Figure 5. Visualization of a blockchain fork event: a new block extends one fork, reconverging the network
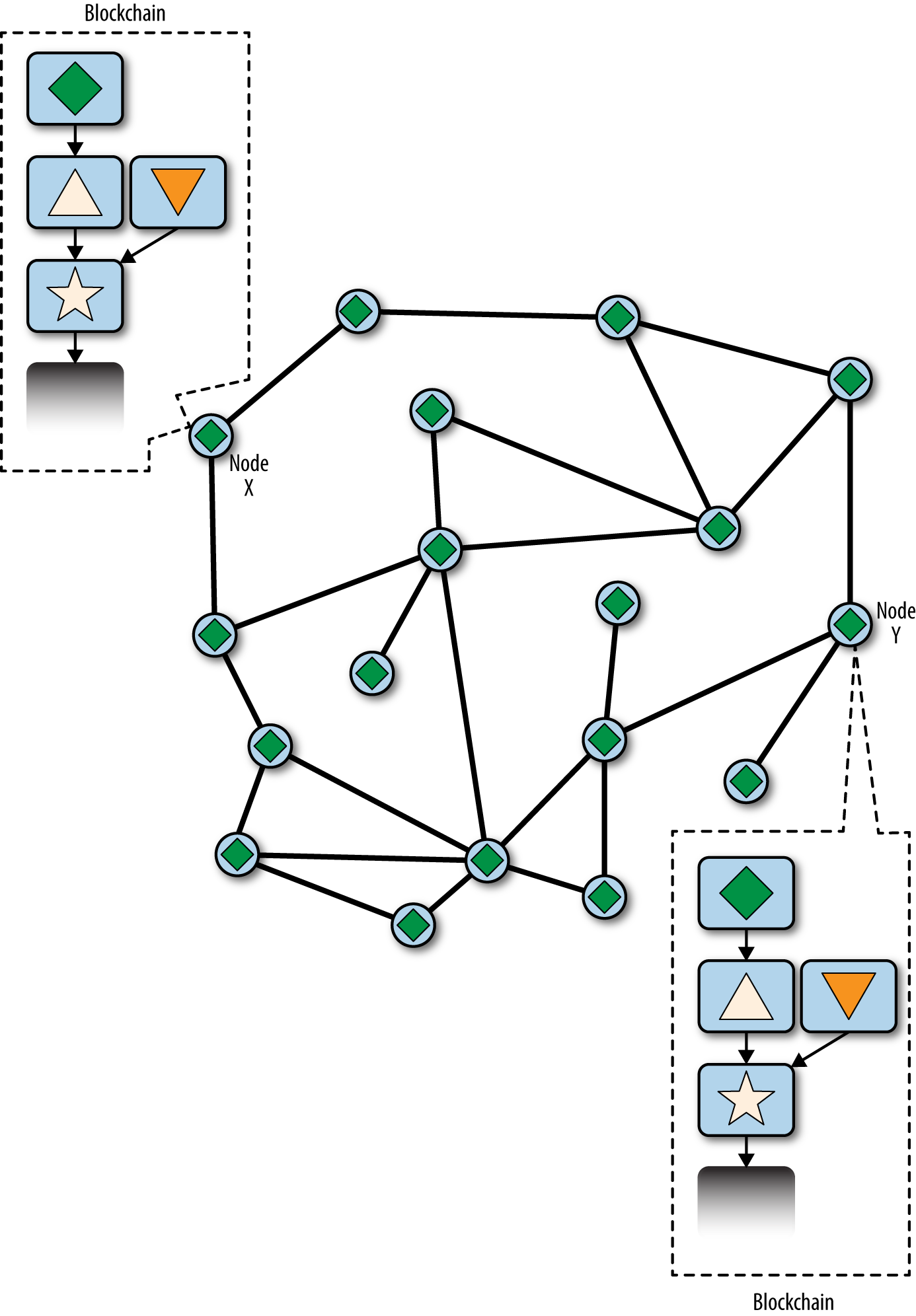
Figure 6. Visualization of a blockchain fork event: the network reconverges on a new longest chain
理論上,如果礦工在前一個分叉的相對面上幾乎同時發現了兩個區塊,那麼這個分叉可能延伸到兩個區塊。然而,發生這種情況的可能性很小。而一個區塊的fork可能每天都出現,而兩個區塊的fork則最多每隔幾周出現一次。
比特幣區塊的10分鐘間隔是快速確認時間(交易結算)和分叉概率之間的設計折中。更快的區塊時間會使交易清除更快,但會導致更頻繁的區塊鏈分叉,而較慢的區塊時間會減少分叉數量,但會降低交易速度。
挖礦和雜湊競賽 Mining and the Hashing Race
比特幣開採是一個極具競爭力的行業,比特幣存在以來雜湊算力每年都會成倍地增加。有些年份的增長反映了技術的完全變化,例如2010年和2011年,當時許多礦工從使用CPU挖礦轉向GPU和現場可程式化邏輯閘陣列(FPGA)。 2013年,通過將SHA256功能直接應用於專門用於挖礦的硅晶片,ASIC挖礦的引入帶來了挖礦能力的又一次巨大飛躍。首批這樣的晶片可以提供比2010年整個比特幣網路更多的挖礦能力。
以下列表顯示了比特幣網路在前8年的運行總雜湊算力:
- 2009
-
0.5 MH/sec–8 MH/sec (16× growth)
- 2010
-
8 MH/sec–116 GH/sec (14,500× growth)
- 2011
-
116 GH/sec–9 TH/sec (78× growth)
- 2012
-
9 TH/sec–23 TH/sec (2.5× growth)
- 2013
-
23 TH/sec–10 PH/sec (450× growth)
- 2014
-
10 PH/sec–300 PH/sec (30× growth)
- 2015
-
300 PH/sec-800 PH/sec (2.66× growth)
- 2016
-
800 PH/sec-2.5 EH/sec (3.12× growth)
在 Total hashing power, terahashes per second (TH/sec) 的圖表中,我們可以看到比特幣網路的雜湊算力在過去兩年中有所增加。如你所見,礦工之間的競爭和比特幣的增長導致雜湊算力(網路中每秒的總雜湊計算數量)呈指數級增長。
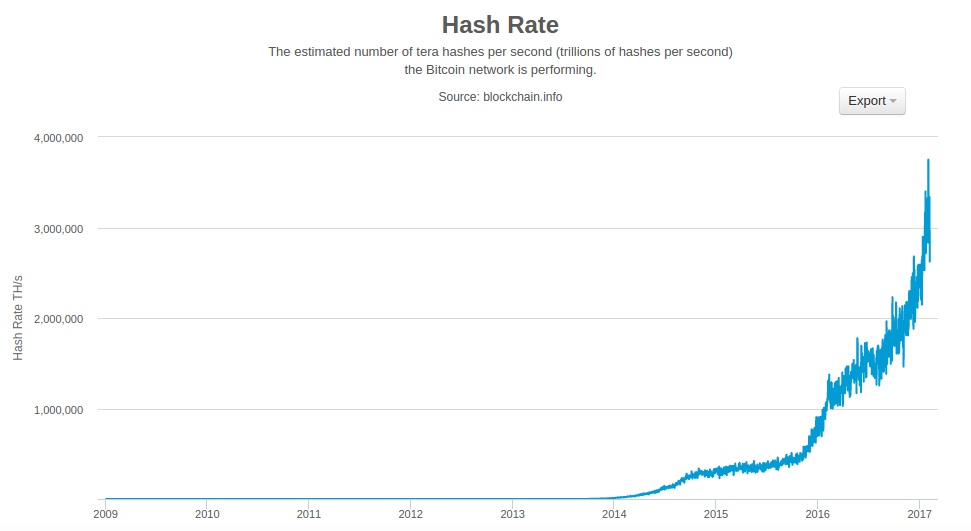
Figure 7. Total hashing power, terahashes per second (TH/sec)
隨著比特幣挖礦的雜湊算力大幅增加,難度也隨之增加。在 Bitcoin’s mining difficulty metric 顯示的圖表中的難度以當前難度相對於最小難度(第一區塊的難度)的比率來衡量。
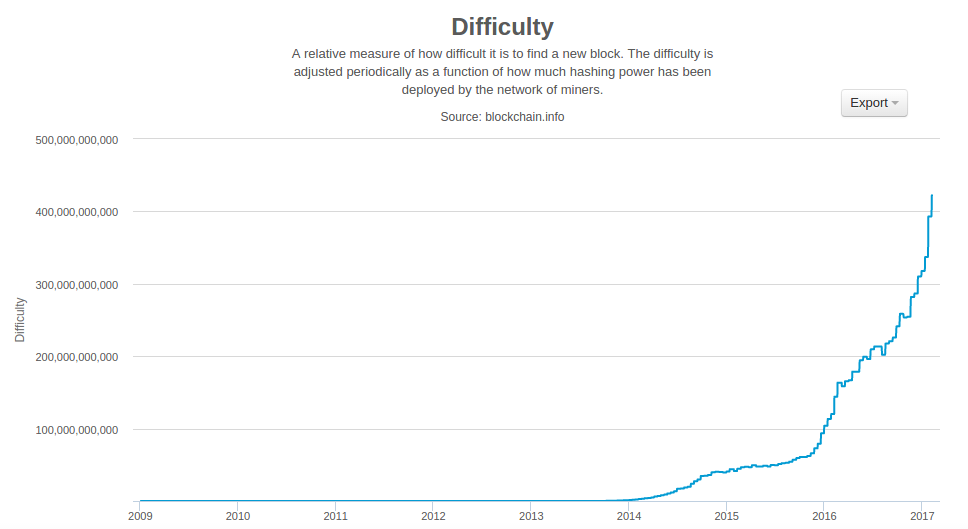
Figure 8. Bitcoin’s mining difficulty metric
在過去的兩年中,ASIC挖礦晶片變得越來越密集,接近硅片製造的極限,功能尺寸(分辨率)為16納米(nm)。目前,ASIC製造商的目標是超越通用CPU晶片製造商,設計14納米功能尺寸的晶片,因為挖礦的盈利能力比通用計算更快地推動這個行業的發展。比特幣礦業沒有更大的飛躍了,因為該行業已經達到摩爾定律的邊緣,該定律指出計算密度大約每18個月翻一番。儘管如此,隨著高密度晶片的競賽與可以部署數千個晶片的高密度數據中心的競賽相匹配,網路的挖礦能力仍然以指數級的速度增長。現在不再關心一區塊晶片可以挖多少礦,而是可以將多少晶片裝入一個設備中,依然可以散熱並提供足夠的算力。
額外隨機數解決方案
自2012年以來,比特幣挖礦已經發展到解決區塊頭結構的根本性限制。在比特幣的早期,礦工可以通過遍歷nonce來找到一個區塊,直到產生的雜湊值低於目標值。隨著困難的增加,礦工經常循環遍歷所有40億個臨時值,而沒有發現區塊。但是,通過更新區塊時間戳以考慮已用時間,這很容易解決。由於時間戳是標題的一部分,所以更改將允許礦工重新遍歷隨機數的值,並獲得不同的結果。但是,一旦挖礦硬體超過 4GH/秒,這種方法變得越來越困難,因為nonce值在不到一秒鐘內就被耗盡了。隨著ASIC挖礦設備開始推進並超過TH /秒雜湊算力,挖礦軟體需要更多的空間來儲存nonce值,以便找到有效的區塊。時間戳可能會稍微延長,但將其變為將來的值會導致該區塊無效。區塊頭中需要新的"更改"來源。解決方案是使用幣基交易作為額外的隨機值的來源。因為幣基腳本可以儲存2到100個字節的數據,所以礦工開始使用這個空間作為額外的nonce空間,允許他們探索更大範圍的區塊標題值以找到有效的區塊。幣基交易包含在merkle樹中,這意味著幣基腳本中的任何更改都會導致merkle根發生更改。八個字節的額外隨機數加上4個字節的"標準"隨機數允許礦工在不必修改時間戳的情況下總共探索 296(一個8,後接28個0)個可能性。如果將來,礦工可以運行所有這些可能性,他們可以修改時間戳。 幣基腳本中還有更多空間用於將來擴展額外的隨機數空間。
礦池
在這個競爭激烈的環境中,獨自工作的礦工(也被稱為獨立礦工)沒有機會。他們發現一個區塊來抵消他們的電力和硬體成本的可能性非常低,所以它代表著賭博,就像玩彩票一樣。即使是最快的ASIC挖礦系統也無法跟上在水力發電附近的巨型倉庫中堆疊數以萬計這些晶片的商業系統。礦工們現在合作形成礦池,彙集他們的算力,在數千名參與者中分享獎勵。通過參與礦池,礦工獲得的整體獎勵佔有率較小,但通常每天都會得到獎勵,從而減少不確定性。
我們來看一個具體的例子。假定礦工已經購買了具有 14,000千兆位/秒(GH/s)或 14TH/s 的雜湊算力的挖礦硬體。 2017年,這臺設備的成本約為2,500美元。硬體在運行時耗電 1375瓦(1.3千瓦),每天耗電33千瓦時,電費非常低,每天花費1美元到2美元。在目前的比特幣難度下,礦工大概每隔4年可以獨自開礦1次。我們如何計算出這個概率?它基於 3EH/sec(2017年)的網路雜湊算力和這個礦工的 14TH/sec 算力:
- P = (14 * 1012 / 3 * 1018) * 210240 = 0.98
…其中 21240 是每4年的區塊數量。礦工每4年找到一個區塊的概率為98%,基於當時的全球雜湊算力。
如果礦工在該時間段內確實找到一個區塊,則可獲得12.5比特幣(每比特幣約1,000美元),一次性收入12,500美元,約7,000美元的淨利潤。但是,在4年內發現區塊的概率取決於礦工的運氣。他可能會在4年內找到兩個區塊並賺取鉅額利潤。或者他可能在5年內找不到一個區塊並遭受更大的經濟損失。更糟糕的是,在當前雜湊算力增長率下,比特幣工作量證明演算法的難度可能會顯著增加,這意味著礦工在硬體過時,必須被更強大的挖礦硬體取代之前最多隻有一年的時間。如果這位礦工參加礦池,而不是等待四年一度的12,500美元的暴利,他將能夠每週賺取大約50美元至60美元。來自礦池的定期收入將幫助他分攤硬體和電力的成本,而不會承擔巨大的風險。硬體在一兩年後仍會過時,風險仍然很高,但在這段時間內收入至少是穩定可靠的。在經濟上,這隻有在非常低的電力成本(每千瓦小時不到1美分)和非常大的規模時才有意義。
礦池通過專門的礦池挖礦協議協調成百上千的礦工。在創建了池中的帳戶後,各個礦工將他們的挖礦設備配置為連接到池伺服器。他們的挖礦硬體在挖礦時仍與池伺服器連接,與其他礦工同步工作。因此,礦池礦工共同努力挖出一區塊,然後分享獎勵。
成功的區塊支付到礦池的比特幣地址,而不是單獨的礦工。池伺服器將定期向礦工的比特幣地址付款,當他們的獎勵的佔有率達到一定的閾值時。通常,池伺服器為提供池挖礦服務收取獎勵的百分比的費用。
加入礦池的礦工將尋找候選區塊解決方案的工作拆分,根據他們的挖礦貢獻贏得"分成"。礦池為獲得股份設定了更廣的目標(較低的難度),通常比比特幣網路的目標要容易1000倍以上。當礦池中的某人成功地開採了一個區塊時,獎勵將由礦池賺取,然後與所有參與努力的礦工按比例分成。
礦池開放給任何礦工,無論大小,專業或業餘。因此,一個礦池將有一些參與者擁有一臺小型挖礦機,而其他人則擁有一個裝滿高端挖礦硬體的車庫。一些將採用幾十千瓦的電力進行挖礦,另一些將運行耗用兆瓦級電力的數據中心。礦池如何衡量個人的貢獻,以公平分配獎勵,而不會有作弊的可能性?答案是使用比特幣的Proof-of-Work演算法來衡量每個礦池礦工的貢獻,但設置的難度較小,因此即使是最小的礦池礦工也能夠頻繁贏得一些佔有率,以便為礦池做出貢獻。通過設定較低的賺取佔有率的難度,該池衡量每個礦工完成的工作量。每當一名礦池礦工發現一個區塊頭雜湊值小於池目標時,她就證明她已完成雜湊工作找到了結果。更重要的是,尋求佔有率的工作以統計上可測量的方式貢獻於總體努力,以找到比比特幣網路的目標更低的雜湊值。成千上萬試圖尋找小雜湊值的礦工最終會找到一個足以滿足比特幣網路目標的礦工。
讓我們回到骰子游戲的比喻。如果骰子玩家投擲骰子的目標是投擲出少於4(整體網路難度)的值,則遊戲池將設定更容易的目標,計算遊戲池玩家投擲結果小於8的次數。當選手擲出少於8(池目標)的值時,他們將獲得佔有率,但是他們沒有贏得比賽,因為他們沒有達到比賽目標(少於4)。池玩家可以更頻繁地獲得更容易的池目標,即使他們沒有實現贏得比賽的更難的目標,也可以非常經常地贏得他們的佔有率。無論何時,其中一名球員將擲出少於4的值,並且贏得比賽。然後,收入可以根據他們獲得的佔有率分配給池玩家。儘管8或更少的目標沒有獲勝,但這是測量玩家擲骰子的公平方法,偶爾會產生少於4的投擲。
類似地,礦池將設置(更高和更容易)的池目標,以確保個體池礦工能夠找到經常低於池目標的區塊頭雜湊值,從而獲得佔有率。每隔一段時間,這些嘗試中的一個會產生一個比比特幣網路目標小的區塊頭雜湊值,使其成為一個有效的區塊,並且整個池都會贏。
管理型礦池
大多數礦池都是"被管理"的,這意味著有一個公司或個人運行池伺服器。池伺服器的所有者稱為 礦池運營者 pool operator ,他向池中礦工收取收入的一定比例費用。
池伺服器運行專門的軟體和池挖礦協議來協調池內礦工的活動。池伺服器還連接到一個或多個完整的比特幣節點,並可直接訪問區塊鏈資料庫的完整副本。這允許池伺服器代表池礦工驗證區塊和交易,從而減輕他們運行完整節點的負擔。對於池礦工而言,這是一個重要的考慮因素,因為完整節點需要具有至少100至150 GB持久性儲存(硬碟)和至少2至4GB內存(RAM)的專用電腦。此外,運行在完整節點上的比特幣軟體需要經常進行監控,維護和升級。由於缺乏維護或缺乏資源而導致的任何停機都會損害礦工的盈利能力。對於許多礦工而言,可以在不運行完整節點的情況下進行挖礦是加入托管池的另一大好處。
池礦工使用挖礦協議(如Stratum(STM)或GetBlockTemplate(GBT))連接到池伺服器。自2012年年底以來,名為GetWork(GWK)的較舊標準大多已經過時,因為它不能輕易支援以 4GH/s 以上的雜湊速率進行挖礦。STM和GBT協議都創建了包含候選區塊頭模板的區塊 模板。池伺服器通過聚合交易構建候選區塊,添加幣基交易(帶有額外的nonce空間),計算merkle根,並鏈接到前一個區塊的雜湊值。然後將候選區塊的頭作為模板發送給每個泳池礦工。然後每個礦池礦工使用區塊模板進行開採,目標比比特幣網路的目標更廣,並將任何成功的結果發送回礦池伺服器以賺取佔有率。
對等礦池 (P2Pool)
被管理的池可能會導致池運營者作弊,他可能會指使礦池努力進行雙重支付交易或使區塊無效(請參閱 共識攻擊 )。此外,集中池伺服器代表單點故障。如果池伺服器關閉或由於拒絕服務攻擊而放慢速度,池中的礦工將無法開採。 2011年,為解決這些集中化問題,提出並實施了一種新的池式挖礦方法:P2Pool,一個沒有中央運營商的對等礦池。
P2Pool通過分散池伺服器的功能工作,實現了稱為 股份鏈 share_chain 的並行的類似區塊鏈的系統。股份鏈是比比特幣區塊鏈難度更低的區塊鏈。股份鏈允許礦池礦工通過以每30秒一個區塊的速度挖出鏈上的佔有率,在去中心化的池中進行合作。股份鏈上的每個區塊都會為參與工作的池礦工記錄相應的股份回報,並將股份從前一個股份區塊中向前移動。當其中一個股份區塊也實現比特幣網路目標時,它會被傳播幷包含在比特幣區塊鏈中,獎勵所有為獲勝股份區塊之前的所有股份作出貢獻的礦池礦工。本質上,與池伺服器跟蹤池礦工的股份和獎勵不同,股份鏈允許所有池礦工使用類似比特幣的區塊鏈共識機制的去中心化共識機制來跟蹤所有股份。
P2Pool出塊比礦池出塊更復雜,因為它要求池礦工運行具有足夠硬碟空間,內存和網路頻寬的專用電腦,以支援完整的比特幣節點和P2Pool節點軟體。 P2Pool礦工將他們的挖礦硬體連接到他們的本地P2Pool節點,該節點通過向挖礦硬體發送區塊來模擬池伺服器的功能。在P2Pool上,個人池礦工構建他們自己的候選區塊,像獨立礦工一樣聚集交易,然後在股份鏈上進行協作。 P2Pool是一種混合型方法,與單獨挖礦相比,具有更精細的支出優勢,也不會像管理型礦池那樣給池操作員太多控制權。
儘管P2Pool降低了礦池運營商的權力集中度,但可以想象,股份鏈本身有51%攻擊的可能性。 P2Pool的廣泛採用並不能解決比特幣本身的51%攻擊問題。相反,P2Pool使比特幣整體更加強大,作為多元化挖礦生態系統的一部分。
共識攻擊
至少從理論上講,比特幣的共識機制很容易受到礦工(或礦池)的攻擊,因為他們試圖利用他們的"雜湊"算力,來實施不誠實或破壞性的目的。如我們所看到的,共識機制取決於大多數礦工出於自身利益誠實行事。然而,如果一名礦工或一群礦工能夠獲得相當大的雜湊算力佔有率,他們就可以攻擊共識機制,從而破壞比特幣網路的安全性和可用性。
重要的是要注意到,共識攻擊只能影響未來的共識,或者至多影響最近的過去(幾十個區塊)。隨著時間的流逝,比特幣的賬本變得越來越不可改變。雖然在理論上,分叉可以在任何深度上實現,但在實踐中,強制執行一個非常深的分叉所需的計算能力是巨大的,這使得舊的區塊實際上是不可變的。共識攻擊也不影響私鑰和簽名演算法(ECDSA)的安全性。共識攻擊不能竊取比特幣,不能在沒有簽名的情況下使用比特幣,不能改變比特幣的方向,也不能改變過去的交易或所有權記錄。共識攻擊只能影響最近的區塊,並在創建未來區塊時導致拒絕服務中斷。
針對共識機制的攻擊場景稱為"51%攻擊"。在這種情況下,一群控制著整個網路的雜湊算力(51%)的礦工勾結起來攻擊比特幣。有了挖出大部分區塊的能力,攻擊的挖礦人員可以在區塊鏈和雙重支付交易中引起有意的"分叉",或者對特定的交易或地址執行拒絕服務攻擊。fork/double-spend攻擊是指攻擊者通過在其下方分叉並在另一個鏈上重新聚合而導致先前確認的區塊無效的攻擊。有了足夠的能力,攻擊者可以使一行中的六個或多個區塊失效,從而導致被認為不可變的交易(六個確認)失效。注意,雙重支付只能在攻擊者自己的交易上執行,攻擊者可以為此生成有效的簽名。如果通過使交易無效,攻擊者可以獲得不可逆的兌換付款或產品,而無需為此付費,那麼重複使用自己的交易就是有利可圖的。
讓我們來看一個51%攻擊的實際例子。在第一章中,我們看了Alice和Bob之間的一筆交易,即一杯咖啡。咖啡館老闆Bob願意接受咖啡的付款,而不需要等待確認(在一個區塊內開採),因為與快速客戶服務的便利性相比,兩次消費一杯咖啡的風險較低。這類似於咖啡店的做法,即接受低於25美元的信用卡支付而無需簽名,因為信用卡退款的風險較低,而延遲交易獲得簽名的成本相對較大。相比之下,以比特幣賣出一件更昂貴的商品,就會有雙重支付攻擊的風險,即買家廣播一項相互競爭的交易,該交易使用相同的輸入(UTXO),並取消支付給商家的款項。雙重支付攻擊可以以兩種方式發生:要麼在確認交易之前,要麼在攻擊者利用區塊鏈fork撤消多個區塊之前。51%攻擊允許攻擊者在新鏈中重複使用自己的交易,從而取消舊鏈中的相應交易。
在我們的例子中,惡意攻擊者Mallory來到Carol的畫廊,購買了一幅美麗的三聯畫,將中本聰描繪為普羅米修斯。Carol以25萬美元的價格將《The Great Fire》的畫作賣給了Mallory。Carol沒有在交易中等待6個或更多的確認,而是在只有一次確認後將畫作交給了Mallory。Mallory與一個共犯Paul一起工作,Paul經營著一個大的礦池。一旦Mallory的交易被包含在一個區塊內,共犯就會發起51%攻擊。Paul指導礦池重新挖與包含Mallory交易的區塊高度相同的區塊,將Mallory對Carol的付款替換為使用相同輸入的雙重支付交易。這種雙重支付交易消耗了相同的UTXO,並將其歸還給Mallory的錢包,而不是支付給Carol,實質上是讓Mallory保留比特幣。然後,Paul引導礦池挖出一個額外的區塊,從而使包含雙重支付交易的鏈比原來的鏈長(在包含Mallory交易的區塊下產生一個fork)。當區塊鏈分叉被解決為支援新的(更長的)鏈時,重複使用的交易將替換為Carol的原始付款。Carol現在丟失了畫作,也沒有收到比特幣付款。在所有這些活動中,Paul的礦池參與者可能不知道重複支付的嘗試,因為他們使用自動的礦工進行挖礦,不能監視每個交易或區塊。
為了防止這種攻擊,出售大價值商品的商人必須至少等待6次確認才能將產品交給買方。或者,商戶應該使用託管多簽名帳戶,在託管帳戶得到資金後再等待幾個確認。確認越長,就越難以執行51%攻擊使交易無效。對於高價值的物品,即使買家需要等待24小時才能交貨,用比特幣付款仍然是方便和有效的,這相當於大約144個確認。
除了雙重支付攻擊之外,共識攻擊的另一個場景是拒絕向特定的比特幣參與者(具體的比特幣地址)提供服務。擁有大部分挖礦能力的攻擊者可以簡單地忽略特定的交易。如果它們包含在由另一個礦機挖的區塊中,攻擊者可以故意對該區塊進行fork和重新挖,再次排除特定的交易。這種類型的攻擊可以導致對特定地址或地址集的持續拒絕服務,只要攻擊者控制了大部分挖礦能力即可。
儘管名字為51%攻擊,實際上並不需要51%的雜湊算力。事實上,這樣的攻擊可以嘗試使用較小比例的雜湊算力。51%僅僅是這種攻擊幾乎可以保證成功的水平。達成共識的攻擊本質上是挖下一個區塊的集團間的拔河,"更強大"的集團更有可能獲勝。使用較少的雜湊算力,成功的可能性就會降低,因為其他礦工用他們"誠實"的挖礦力量控制某些區塊的生成。可以這樣看,攻擊者的雜湊算力越強,他故意創建的分叉越長,他在最近的一段時間內可以使更多的區塊失效,或者在未來可以控制更多的區塊。安全研究小組使用統計建模來宣稱,只要30%的雜湊算力,各種類型的共識攻擊都是可能的。
可以說,比特幣的雜湊算力大幅增加,使得它不會受到任何一個礦工的攻擊。對於一個單獨的礦工來說,不可能控制超過總開採能力的一小部分。然而,由礦池引起的集中控制帶來了礦池運營商進行盈利性攻擊的風險。託管池中的池運營商控制候選區塊的構造,並控制包含哪些交易。這使池運營商能夠排除交易或引入雙重支付交易。如果這種濫用權力的行為是以一種有限而微妙的方式進行的,那麼池運營商可以在不被注意的情況下從共識攻擊中獲利。
然而,並非所有的攻擊者都是受利潤驅動的。一個潛在的攻擊場景是,攻擊者打算破壞比特幣網路,而不可能從這種破壞中獲利。破壞比特幣的惡意攻擊將需要鉅額投資和祕密計劃,可以想象,攻擊者可能是資金充裕、最有可能是政府支援的攻擊者。另外,資金充裕的攻擊者可以通過同時收集挖礦硬體、勾結池運營商、以及拒絕服務攻擊其他池來攻擊比特幣的共識。所有這些設想在理論上都是可能的,但隨著比特幣網路的總體雜湊能力繼續呈指數級增長,它們越來越不切實際。
毫無疑問,一場嚴重的共識攻擊將在短期內削弱人們對比特幣的信心,可能導致比特幣價格大幅下跌。然而,比特幣網路和軟體一直在不斷展,因此,比特幣社區會立即應對輿論攻擊,使比特幣更加穩健。
共識規則的改變
共識規則決定了交易和區塊的有效性。這些規則是所有比特幣節點之間協作的基礎,並負責將所有本地視圖匯聚到整個網路的一個一致的區塊鏈中。
雖然共識規則在短期內是不變的,並且必須在所有節點之間保持一致,但是從長期來看,它們並不是不變的。為了進化和發展比特幣系統,規則必須不時變化,以適應新的特性、改進或bug修復。然而,與傳統的軟體開發不同,對共識系統的升級要困難得多,需要所有參與者之間的協調。
硬分叉
在 [fork] 中,我們研究了比特幣網路可能會有短暫的分歧,在短時間內,在區塊鏈的兩個不同分支的網路中有兩個部分。我們看到這個過程是如何自然地發生的,作為網路正常運行的一部分,以及在挖一個或多個區塊之後,網路如何在公共區塊鏈上重新收斂。
在另一種情況下,網路可能會分化成以下兩個鏈:共識規則的改變。這種類型的分叉稱為 硬分叉 hard fork,因為在分叉之後,網路不會重新聚合到單個鏈上。相反,這兩條鏈是獨立進化的。當網路的一部分在一組不同於網路其他部分的共識規則下運行時,就會出現硬分叉。這可能是由於錯誤或共識規則執行過程中故意更改而導致的。
硬分叉可以用來改變共識規則,但是它們需要系統中所有參與者之間的協作。任何不升級到新的共識規則的節點都不能參與共識機制,並在硬分叉時被迫進入一個單獨的鏈。因此,硬分叉引入的更改可以被認為是不"向前兼容"的,因為在非升級的系統中不能再處理新的共識規則。
讓我們通過一個例子來查看硬分叉的結構。
[blockchainwithfork] 展示了區塊鏈和兩個分叉,在區塊高度為4的地方,出現一個單區塊分叉。這是我們在 [fork] 中看到的自發性分叉類型。在第5區塊的挖礦中,網路在一個鏈上重新聚合,分叉被解決。
Figure 9. A blockchain with forks
然而,稍後,在區塊高6處,出現硬分叉。讓我們假設客戶端的新實現隨共識規則的更改而釋放。從區塊高度7開始,運行這個新實現的礦工將接受一種新的數位簽章類型,我們稱之為"Smores"簽名,它不是基於ECDSA的。緊接著,運行新實現的節點將創建一個包含Smores簽名的交易,並運行最新軟體的礦工,挖包含該交易的區塊7b。
任何沒有升級軟體以驗證Smores簽名的節點或礦工現在都無法處理第7b區塊。從他們的角度來看,包含Smores簽名的交易和包含該交易的block 7b都是無效的,因為它們是基於舊的共識規則進行評估的。這些節點將拒絕交易和區塊,不會傳播它們。任何使用舊規則的挖礦人員都不會接受第7b區塊,並將繼續挖父區塊為第6區塊的候選區塊。事實上,如果使用舊規則的礦工連接到的所有節點都遵守舊規則,因此不傳播該區塊,那麼他們甚至可能不會接收到block 7b。最終,他們將能夠挖第7a區塊,該區塊在舊規則下是有效的,不包含任何帶有Smores簽名的交易。
這兩條鏈從這一點開始繼續偏離。"b"鏈上的礦工將繼續接受和挖出包含Smores簽名的交易,而"a"鏈上的礦工將繼續忽略這些交易。即使block 8b不包含任何經過Smores簽名的交易,"a"鏈上的礦工也不能處理它。對他們來說,它似乎是一個孤立的區塊,因為它的父"7b"不被認為是一個有效的區塊。
硬分叉:軟體,網路,挖礦,和鏈
對於軟體開發人員來說,"fork" 這個詞還有另外一個含義,給 "hard fork" 這個詞增加了混淆。在開放源碼軟體中,當一組開發人員選擇遵循不同的軟體路線圖並啟動一個開放源碼項目的競爭性實現時,就會出現一個fork。我們已經討論了導致硬分叉的兩種情況:共識規則中的錯誤和共識規則的故意修改。在故意改變共識規則的情況下,軟分叉優先於硬分叉。然而,對於這種類型的硬分叉,必須開發、採用和啟動共識規則的新軟體實現。
試圖改變共識規則的軟體分叉的例子包括Bitcoin XT、Bitcoin Classic,以及最近的Bitcoin Unlimited。然而,這些軟體的分叉都沒有帶來一個硬的叉。雖然軟體fork是一個必要的先決條件,但它本身並不足以出現硬fork。要實現一個硬的fork,必須採用競爭的實現,以及由礦商、錢包和中間節點啟用的新規則。相反,有許多Bitcoin Core的替代實現,甚至是軟體分支,它們不會改變共識規則,也不會排除bug,它們可以在網路上共存並互操作,而不會造成硬分叉。
共識規則在交易或區塊的驗證中可能以明顯和明確的方式存在差異。這些規則還可能在更微妙的方面有所不同,比如在適用於比特幣腳本或數位簽章等密碼基元的共識規則的實現上。最後,由於系統限制或實現細節所造成的隱式共識約束,共識規則可能會因未預期的方式而有所不同。在將Bitcoin Core0.7升級到0.8的過程中,在意料之外的硬分叉中可以看到後者的一個例子,這是由於用於儲存區塊的Berkley DB實現的限制造成的。
從概念上講,我們可以把硬分叉看作是分四個階段發展的:軟體分叉、網路分叉、挖礦分叉和鏈分叉。
當開發人員創建修改了共識規則的客戶端替代實現時,流程就開始了。
當這個分叉實現部署到網路中時,一定比例的礦工、錢包用戶和中間節點可以採用並運行這個實現。產生的分叉將取決於新的共識規則是否適用於區塊、交易或系統的其他方面。如果新的共識規則與交易相關,那麼在新規則下創建交易的錢包可能會生成一個網路分叉,然後當交易被挖出到一個區塊時,會出現一個硬分叉。如果新規則涉及到區塊,那麼當在新規則下挖出區塊時,硬分叉過程將開始。
首先,網路將會分叉。基於共識規則的原始實現的節點將拒絕在新規則下創建的任何交易和區塊。此外,遵循原始共識規則的節點將臨時禁止並斷開與發送這些無效交易和區塊的任何節點的連接。因此,網路將被劃分為兩個部分:舊節點只會繼續連接舊節點,新節點只會連接到新節點。基於新規則的單個交易或區塊將在網路中產生連鎖反應,並導致分成兩個網路。
一旦一名礦工使用新規則開採一個區塊,開採算力和鏈也將分叉。新礦工將在新區塊的頂部挖礦,而老礦工將在舊規則的基礎上開採一個單獨的鏈條。分割後的網路將使在獨立的共識規則下操作的礦工不可能接收到彼此的區塊,因為他們連接到兩個獨立的網路。
分叉的礦工和難度
當礦工們分別開採兩個不同的鏈條時,它們的雜湊算力就會被分割開來。在這兩個鏈之間,可以按任何比例分割挖礦算力。新規則可能只會被少數人遵守,或者被絕大多數算力的礦工遵守。
例如,我們假設 80% —— 20% 分割,大多數挖礦算力使用新的共識規則。假設分叉在重新設定目標的階段後立即開始。
這兩個鏈將從重新設定目標階段繼承難度。新的共識規則將有80%的先前的算力委託給他們。從這條鏈的角度來看,與前一時期相比,挖礦算力突然下降了20%。平均每12.5分鐘就會發現一些區塊,這代表了延伸這條鏈的挖礦算力下降了20%。這種區塊發行速度將持續下去(除非雜湊功率發生變化),直到2016年區塊被開採,這將需要大約25,200分鐘(每區塊12.5分鐘),或17.5天。17.5天后,重新設定目標,難度調整(減少20%),基於該鏈中雜湊算力的減少,再次生成10分鐘的區塊。
在舊規則下,只有20%的雜湊算力,將面臨更加困難的任務。在這條鏈條上,現在平均每50分鐘開採一區塊。接下來2016區塊礦的難度將不會調整,這將需要100,800分鐘,或者大約10周。假設每個區塊有固定的容量,這也將導致交易容量減少5倍,因為每小時記錄交易的區塊更少。
有爭議的硬分叉
這是共識軟體開發的曙光。正如開源開發改變了軟體的方法和產品,並隨之創造了新的方法、新的工具和新的社區,共識軟體開發也代表了電腦科學的一個新的前沿。從比特幣發展路線圖的辯論、實驗和磨難中,我們將看到新的開發工具、實踐、方法和社區出現。
硬分叉被認為是有風險的,因為它們迫使少數人要麼升級,要麼留在少數人的鏈條上。許多人認為,將整個系統分割成兩個相互競爭的系統的風險是不可接受的。因此,許多開發人員不願意使用硬分叉機制來實現對共識規則的升級,除非整個網路幾乎一致支援。任何沒有得到一致支援的硬分叉提議都被認為太"有爭議",不可能在不危及系統分割的情況下嘗試。
硬分叉的問題在比特幣開發界引起了極大的爭議,尤其是當它涉及對控制最大區塊大小限制的共識規則的任何擬議更改時。一些開發人員反對任何形式的硬分叉,認為這樣做風險太大。另一些人認為,硬分叉機制是升級共識規則的重要工具,以避免"技術債務",並與過去徹底決裂。最後,一些開發人員認為硬分叉是一種應該很少使用的機制,需要進行大量的預先規劃,而且只有在達成幾乎一致的意見下才能使用。
我們已經看到了解決"硬分叉"風險的新方法的出現。在下一節中,我們將討論軟分叉,以及BIP-34和BIP-9方法,用於通知和激活共識的修改。
軟分叉
並非所有共識規則的改變都會導致硬分叉。只有共識的變更是向前不兼容的,才會產生一個分叉。如果更改的實現方式使得未修改的客戶端仍然認為交易或區塊在以前的規則下是有效的,那麼更改可以在沒有分叉的情況下發生。
引入soft fork這一術語,將這種升級方法與"硬分叉"區分開來。實際上,軟分叉根本不是分叉。軟分是對共識規則的向前兼容更改,允許未升級的客戶端繼續與新規則一致地運行。
軟分叉的一個方面並不明顯,即軟分叉升級只能用於約束共識,而不能擴展它們。為了向前兼容,在新規則下創建的交易和區塊也必須在舊規則下有效,反之亦然。新規則只能限制什麼是有效的;否則,在舊規則下被拒絕時,它們將觸發硬分叉。
軟分叉可以通過多種方式實現 —— 這個術語不指定特定的方法,而是一組方法,它們都有一個共同點:不需要所有節點進行升級,也不需要強制不升級的節點退出共識。
軟分叉重定義的 NOP 操作碼
基於對NOP操作碼的重新解釋,比特幣已經實現了許多軟分叉。比特幣腳本中有10個操作碼,從NOP1到NOP10。根據共識規則,在腳本中存在這些操作碼被解釋為無效的操作符,這意味著它們沒有效果。執行在NOP操作碼之後繼續,就好像它不在那裡一樣。
因此,軟fork可以修改NOP程式碼的語義,從而賦予它新的含義。例如,BIP-65 ( CHECKLOCKTIMEVERIFY ) 重新解釋了NOP2操作碼。實現BIP-65的客戶端將NOP2解釋為 OP_CHECKLOCKTIMEVERIFY,並對UTXO強加一個絕對鎖時間共識規則,在他們的鎖定腳本中包含這個操作碼。這種更改是一個軟分叉,因為在BIP-65下有效的交易對於任何不實現(不知道)BIP-65的客戶端也是有效的。對於舊的客戶端,該腳本包含一個NOP程式碼,該程式碼將被忽略。
軟分叉升級的其他方法
對NOP操作碼的重新解釋是有計劃的,也是共識升級的明顯機制。然而,最近又引入了另一種軟分叉機制,它不依賴於NOP操作碼進行非常特定的共識更改。這在 [segwit] 中有更詳細的討論。Segwit是對交易結構的架構更改,它將解鎖腳本(見證)從交易內部移動到外部資料結構(隔離它)。Segwit最初被設想為硬分叉升級,因為它修改了基本結構(交易)。2015年11月,一位致力於Bitcoin Core的開發人員提出了一種機制,可以將segwit作為一種軟分叉引入。用於此的機制是對在segwit規則下創建的UTXO的鎖定腳本的修改,這樣未修改的客戶端就可以通過任何解鎖腳本贖回鎖定腳本。因此,可以引入segwit,而不需要每個節點升級或從鏈上拆分:這是一個軟分叉。
很有可能還有其他的,但有待發現的機制,通過這些機制,升級可以以一種向前兼容的方式作為軟分叉。
針對軟分叉的批評
基於NOP操作碼的軟分叉相對來說是沒有爭議的。NOP操作碼放在比特幣腳本中,明確的目標是允許非破壞性升級。
然而,許多開發人員擔心其他的軟分叉升級方法會導致不可接受的折衷。對軟分叉變化的常見批評包括:
- 技術債務 Technical debt
-
因為軟分叉比硬分叉升級更復雜,他們引入了 technical debt ,這個術語指的是由於過去的設計權衡而增加了未來的程式碼維護成本。程式碼的複雜性反過來又增加了錯誤和安全漏洞的可能性。
- 驗證放鬆 Validation relaxation
-
未修改的客戶端認為交易是有效的,而不評估修改後的共識規則。實際上,未修改的客戶端不使用所有共識規則進行驗證,因為它們對新規則視而不見。這適用於基於NOP的升級,以及其他軟分叉升級。
- 不可逆的更新 Irreversible upgrades
-
因為軟分叉創建具有附加共識約束的交易,它們在實踐中成為不可逆轉的升級。如果一個軟分叉升級在啟用後被撤銷,根據新規則創建的任何交易都可能導致舊規則下的資金損失。例如,如果CLTV交易是在舊規則下計算的,則沒有timelock約束,可以在任何時候使用它。因此,批評人士認為,由於錯誤而不得不取消的失敗軟分叉幾乎肯定會導致資金損失。
使用區塊版本的軟分叉信號
由於軟分叉允許未修改的客戶端繼續在共識範圍內運行,因此"激活"軟分叉的機制是通過礦工發出準備就緒的信號:大多數礦商必須同意他們已經準備好並願意執行新的共識規則。為了協調他們的行動,有一個信號機制允許他們表示對共識規則變更的支援。該機制於2013年3月引入BIP-34激活,2016年7月被BIP-9激活取代。
BIP-34 信號和啟用
在BIP-34中,第一個使用了區塊版本號欄位的實現,允許礦工發出信號,表示已經準備好進行特定的共識規則更改。在BIP-34之前,區塊版本號根據約定設置為"1",不以共識執行。
BIP-34定義了一個共識規則變更,要求幣基交易的coinbase欄位(輸入)包含區塊高度。在BIP-34之前,這個欄位可以包含任意數據。激活BIP-34之後,有效的區塊必須在coinbase的起始處包含特定的區塊高度,並用大於或等於"2"的版本號進行標識。
為了表明BIP-34的變化和激活,礦工將區塊版本設置為"2"而不是"1"。這並沒有立即使版本"1"區塊無效。一旦激活,版本"1"區塊將變得無效,並且所有版本"2"區塊將被要求在coinbase欄位中包含區塊高度才有效。
BIP-34基於1000區塊的滾動窗口定義了兩步激活的機制。礦工將通過構建具有"2"作為版本號的區塊來表示他或她對BIP-34的個人準備狀態。嚴格地說,這些區塊並不需要遵守在幣基交易中包含區塊高度的新共識規則,因為共識規則尚未激活。共識規則分兩步啟動:
-
如果75%(最近1000個區塊中的750個)標有版本"2",則版本"2"區塊必須在幣基交易中包含區塊高度,否則它們將被視為無效。版本"1"區塊仍然被網路接受,並且不需要包含區塊高度。新舊共識規則在此期間共存。
-
當95%(最近1000個區塊中的950個)為版本"2"時,版本"1"區塊不再被視為有效。版本"2"區塊只有在幣基中包含區塊高時(按照之前的閾值)才有效。此後,所有區塊必須符合新的共識規則,並且所有有效區塊必須包含在幣基交易中的區塊高度。
在BIP-34規則下成功發送信號和啟用後,該機制被再次使用兩次以啟用軟分叉:
在啟用BIP-65後,BIP-34的信號傳導和啟用機制退役並被接下來描述的BIP-9信號傳導機制取代。
BIP-9 信號和啟用
BIP-34,BIP-66和BIP-65使用的機制成功地啟用了三個軟分叉。但是,它被替換了,因為它有幾個限制:
-
通過使用區塊版本的整數值,一次只能啟用一個軟分叉,因此需要軟分叉建議之間的協調,並就其優先級和排序達成一致。
-
此外,由於區塊版本增加,該機制沒有提供直接的方式來拒絕更改,然後提出不同的更改。如果老客戶端仍在運行,他們可能會錯誤地將信號發送給新的更改,作為先前拒絕的更改的信號。
-
每次新的更改不可避免地減少了未來更改的可用區塊版本。
BIP-9 被提出以克服這些挑戰,提高實施未來變革的速度和容易度。
BIP-9 將區塊版本解釋為位域而不是整數。由於區塊版本最初被用作整數使用,版本號1至4,因此有29位可用的位,可用於獨立同時發出29個不同提案的準備就緒信號。
BIP-9 還設置信號和啟用的最長時間。這樣,礦工不需要永遠發出信號。如果提案在 TIMEOUT 期限內(在提案中定義)未啟用,則提議被視為被拒。該建議可能會重新提交以用不同的位進行信號傳輸,從而更新啟用期。
此外,在超過 TIMEOUT 並且某個功能被激活或拒絕之後,信號位可以被重新用於其他功能而不會造成混淆。因此,多達29個變化可以並行發送,TIMEOUT 之後可以"循環"以提出新的更改。
|
Note
|
雖然信號位可以重複使用或循環使用,但只要投票期不重疊,BIP-9的作者建議只有在必要時才能重新使用位;由於舊軟體中的錯誤而可能發生意外行為。總之,我們不應該期望看到重用,直到所有29位被使用過一次。 |
建議的更改由包含以下欄位的資料結構標識:
- name
-
用於區分提案的簡短說明。大多數情況下,描述該建議的BIP為"bipN",其中N是BIP編號。
- bit
-
0 到 28, 礦工用來表示批准該提案的區塊版本中的位。
- starttime
-
信號開始的時間(基於過去中值時間,MTP),在此之後,該位的值被解釋為該提議的信號準備就緒。
- endtime
-
如果更改未達到啟用閾值,則認為拒絕的時間點(基於MTP)。
與BIP-34不同,BIP-9基於2016個區塊的難度重新設定目標階段計算整個區間的啟用信號。對於每個重新定位週期,如果支援提案的信號的區塊的總數超過95%(2016區塊中1916區塊),則該提議將在下一個重新設定目標階段內啟用。
BIP-9 提供了一個提案狀態圖,以說明提案的各個階段和狀態轉換,如 BIP-9 state transition diagram 中所示。
一旦參數在比特幣軟體中已知(定義),提案就以 DEFINED 狀態開始。對於MTP在開始時間之後的區塊,提案狀態將轉換為 STARTED。如果在重新設定目標週期內超過投票閾值並且沒有超時,則提案狀態轉換為 LOCKED_IN。一個重新設定目標週期後,提案變為 ACTIVE 。一旦它們達到該狀態,建議一直保持 ACTIVE 狀態。如果在達到投票閾值之前超時,提案狀態更改為 FAILED,表示被拒絕的提案。 FAILED 提案永遠處於該狀態。
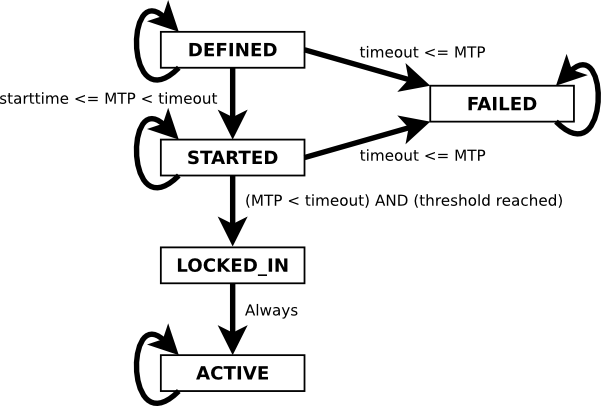
Figure 10. BIP-9 state transition diagram
BIP-9 首先用於激活 CHECKSEQUENCEVERIFY 和相關的 BIP(68,112,113)。名為"csv"的提案已於2016年7月成功啟用。
共識軟體開發
共識軟體不斷發展,關於改變共識規則的各種機制的討論很多。就其本質而言,比特幣在協調和共識變化方面設置了非常高的標準。作為一個分散的系統,它沒有"權威",可以將其意志強加給網路的參與者。權力分散在礦工,核心開發人員,錢包開發人員,交易所,商戶和最終用戶等多個選區之間。任何這些選區都不能單方面做出決定。例如,儘管礦工理論上可以通過簡單的大多數(51%)改變規則,但他們受到其他選區同意的限制。如果他們單方面行事,其他參與者可能會拒絕跟隨他們,從而使經濟活動停留在少數鏈中。如果沒有經濟活動(交易,商人,錢包,交易所),礦工們將會挖到毫無價值的硬幣。權力的分散意味著所有的參與者必須協調,否則就不能做出改變。現狀是這個系統的穩定狀態,如果大多數人達成共識,則系統處於只有很少變化的穩定狀態。軟分叉的95%閾值反映了這一現實。
認識到共識的發展沒有完美的解決方案是很重要的。硬分叉和軟分叉都涉及權衡。對於某些類型的變化,軟分叉可能是更好的選擇;對於其他人來說,硬分叉可能是更好的選擇。沒有完美的選擇;都有風險。共識軟體開發的一個不變特徵是變革難度大,共識強制妥協。
一些人認為這是共識體系的弱點。隨著時間的推移,你可能會像我一樣,認為它是這個系統最強大的力量。